*본 내용은 논문의 상세한 분석이 아닌, 간단한 복기용 정리입니다.
논문 링크: https://arxiv.org/abs/1611.07004
Introduction: Pix2Pix with cGAN

Pix2Pix은 Conditional GAN에 기반한 모델인데요, 이름과 같이 image-to-image task를 수행하는 GAN입니다. Image-to-image이기 때문에, condition 또한 image가 되어야 되겠죠? Condition으로 image를 넣어주고, output 또한 image로 받아냅니다. 위 그림을 보시면 스케치를 주면 실제 사진과 같은 결과를 출력하기도 하고, 이렇게 낮의 사진을 넣으면 밤의 사진을 만들어내기도 합니다. 보통 저해상도에서 고해상도의 이미지를 만들 때 사용합니다.
Recap: Conditional GAN
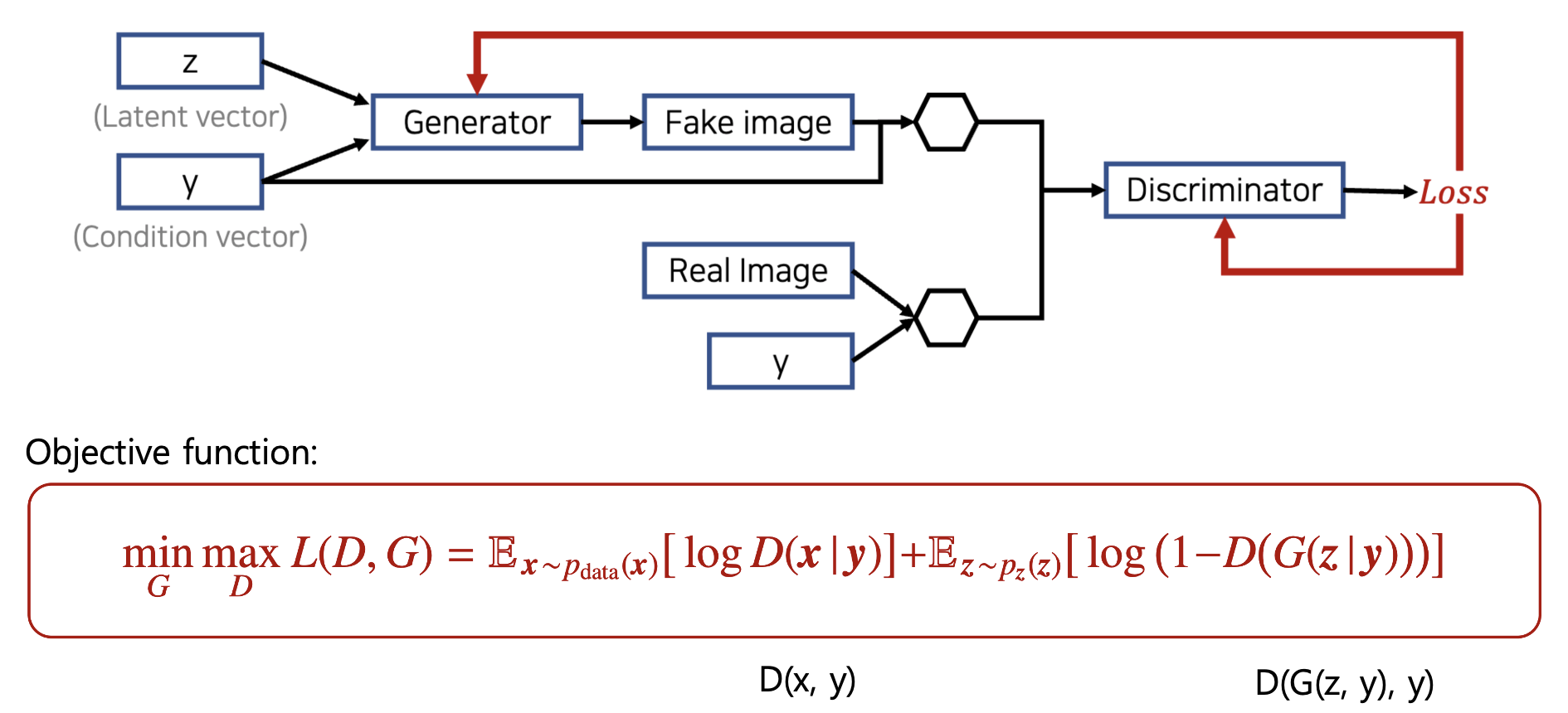
기본 GAN에서 우리가 원하는 특정한 이미지를 생성하고 싶을 때, 이 condition vector을 추가하여 구할 수 있다고 했습니다. 숫자 손글씨 MNIST 데이터셋을 예시를 들면, 예를 들어 2라는 글자만 생성하고 싶다면, one-hot encoding된 label ([0 0 1 0 0 … ])을 추가로 넣어 주면 됩니다. 아래 D(x|y)와 D(x,y)는 같은 표현인데요, 그냥 input에 condition (y)를 추가로 입력한다는 의미입니다.
Method: Pix2Pix with cGAN
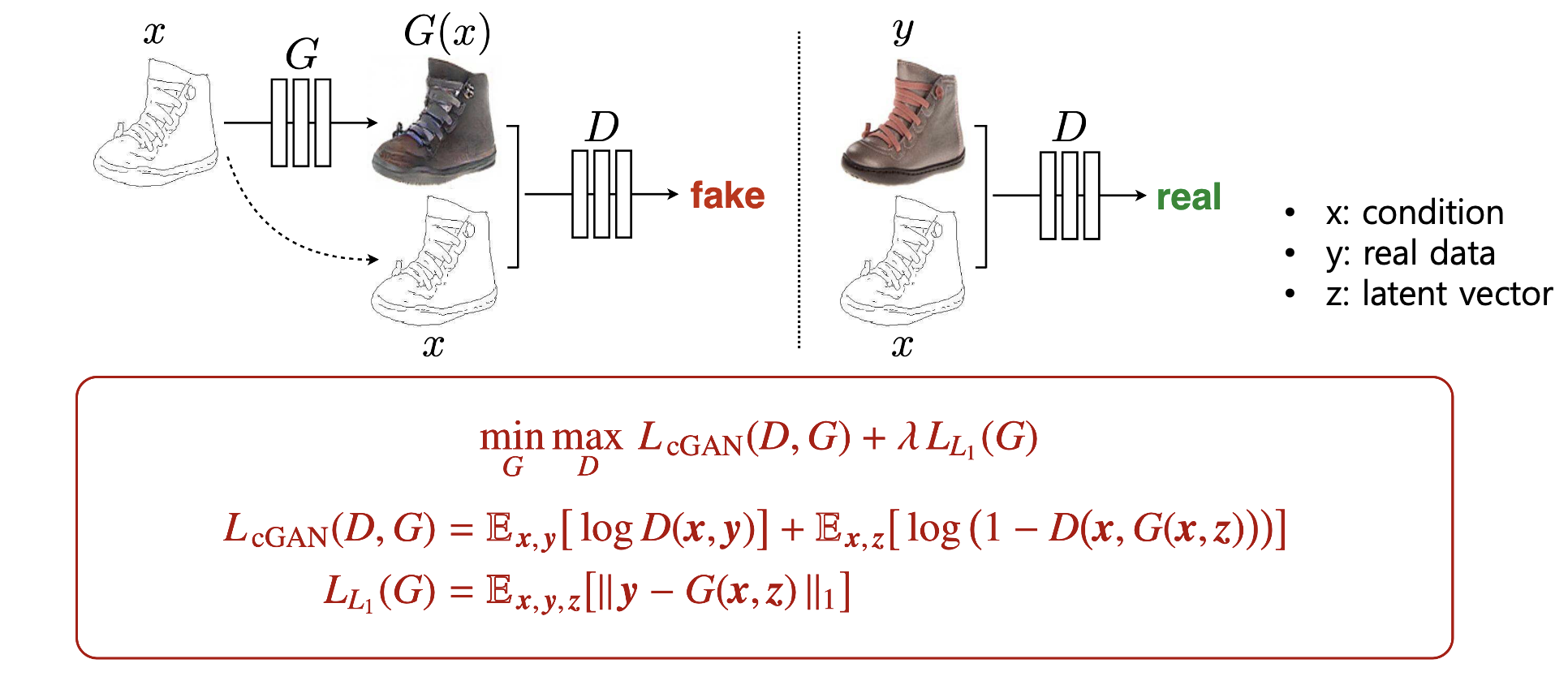
이제 다시 Pix2Pix를 보시면, 아까 보시던 알파벳이랑 좀 달라서 여기 표시를 했는데요. 여기선 x가 추가로 넣어주는 condition, y가 real data, z가 latent vector입니다. 그림 보시는 것과 같이 Conditional CAN과 구조는 똑같습니다. 대신 아까는 vector였던 condition이 여기서는 image의 형태로 들어갑니다. 그래서 여기 밑의 목적함수를 보시면, cGAN 부분에서 real data y가 들어오고, latent vector z가 이렇게 들어올 때, Discriminator에 넣어주기 전에 항상 condition인 x가 붙어서 들어갑니다. 네 완전 똑같죠. condition으로 image를 넣어주는 것 밖에 없습니다. 이렇게 이전의 cGAN과 마찬가지로 Pix2Pix에서의 CGAN 부분 목적함수도 Real data를 그려주는 역할을 합니다. 이제 여기 남아 있는 L1 distance term에 대해서 알아보겠습니다.
Background: Frequency in images
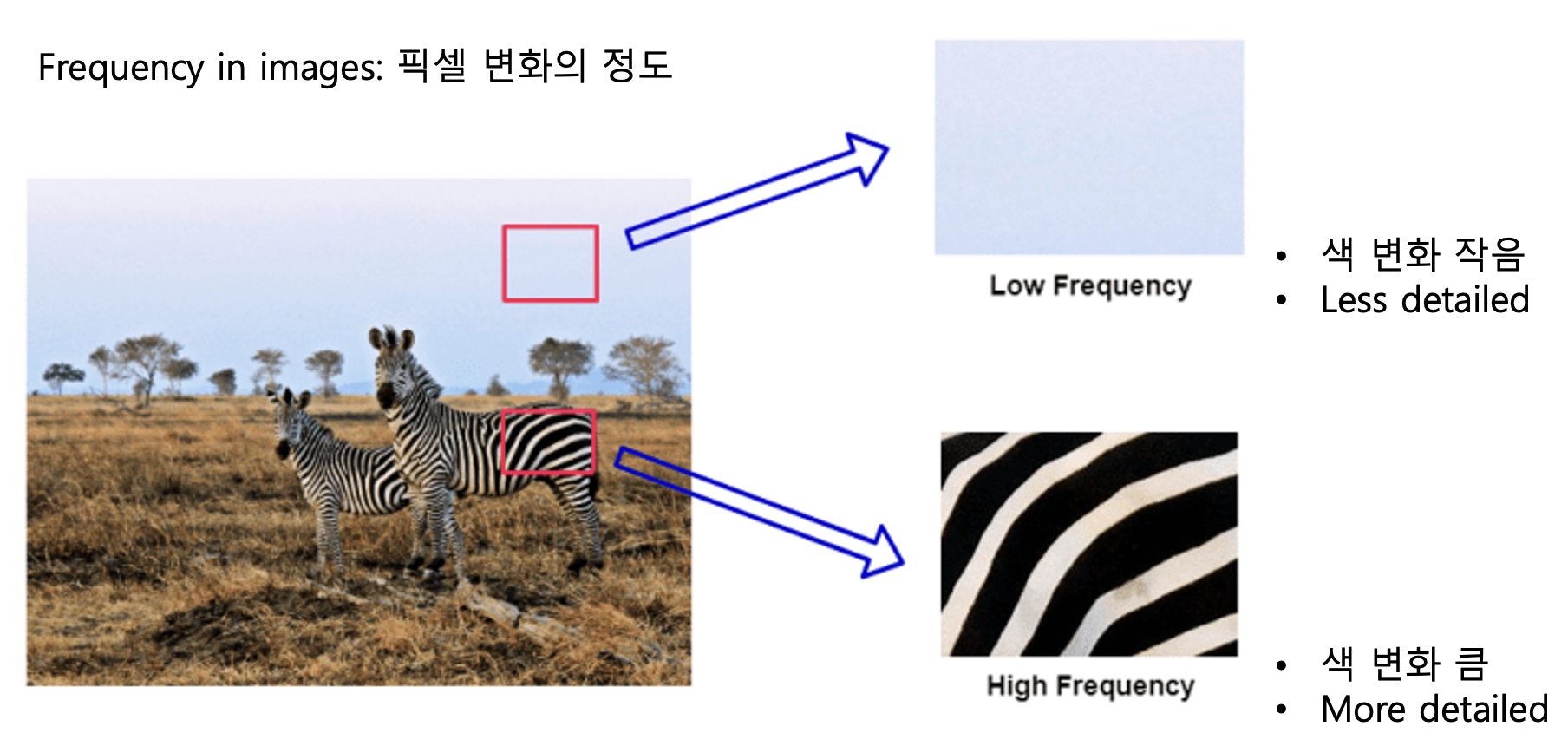
그 전에 용어 정리부터 하겠습니다. Frequency라는 단어는 image에서는 “픽셀 변화의 정도”로 사용됩니다. 왼쪽의 그림에서 하늘의 경우, 색의 변화가 적습니다. 그래서 low frequency이고요. 반면 아래의 얼룩말 부분의 경우에는 색 변화가 극적이고 들쭉날쭉합니다. 이러한 부분을 high frequency라고 하는데요. 이따가 보시면 아시겠지만, 물체의 경계 부분이 high frequency에 속합니다.
Background: L1/L2 loss

이제 L1, L2 distance term에 대해서 보면, 아시다시피 L1은 절댓값을 사용하고, L2는 유클리디안 거리니까 제곱을 사용하여 거리를 표현하죠. 그런데 이 제곱 때문에, L2 Loss는 데이터셋에 이상치가 있는 경우, 그 이상치가 생성 데이터를 지배해버리는 특성을 가집니다. 여기 오른쪽 예시만 보셔도, 10 때문에 L2 loss가 완전 튀어버렸죠?

그래서 이미지의 입장으로 생각하면, 색이 급격하게 변하는 high frequency 부분 즉, 물체의 경계 부분이 이상치가 많이 포함되어 있는 것이겠죠? 그래서 L2보다는 L1이 그런 부분을 잘 표현합니다. 뭐 low-frequency인 부분에서는 L1, L2 둘 다 상관 없이 잘 표현합니다. 여기 Input을 주고, Ground Truth에 대해 L1만을 사용하여 이미지를 생성한 사진인데요. 보시면 뿌옇습니다. 이게 만약에 L2로 바뀌면 훨씬 이 경계를 완전히 검출하지 못하고 더 뿌옇게 만들어지게 됩니다.
여기 Generator에 cGAN만을 사용해서 학습을 하면, 얘는 물체랑은 상관 없이 경쟁을 통해 학습하여 생성하므로 선명하게 사진이 나오지만, 아무래도 GAN의 고질적 문제인 안정성 측면에서 이상한 그림들이 생기는 문제가 있습니다.
따라서 이 둘을 함께 썼을 때, L1이 low-frequency 부분을, cGAN이 high-frequency 부분을 담당하여 아주 sharp한 결과를 보여준다고 논문에서 설명합니다.

그래서 여기 코드 간단히 보시면 여기 conditional GAN을 위해서 MSE Loss를 사용하고요. 여기 L1 loss도 정의해서 오른쪽 학습 과정에서 사용합니다.
Generator Architecture

Generator에서는 U-net을 사용해서 이미지를 생성하는데요. 여기 Up-Sampling할 때, Skip-Connection을 통해서 픽셀 위치나 이런 정보를 잘 전달합니다. 여기 Encoder-Decoder 구조에 Skip Connection 더하고 안 더하고가 이렇게 차이가 난다고 하네요. 여기 위에 사진은 원본 이미지의 구조가 제대로 전달 되지 않은 것을 보실 수 있습니다.

그래서 코드를 보시면, 여기 Encoder 모델의 출력값을 다시 input으로 받아서, skip_input으로 사용될 수 있게 합니다. 그래서 기본적으로 여기 입력 x가 들어왔을 때, 다들 아시다시피 U-net 기본 구조를 통해서 Transpose Convolution을 수행해서 사이즈를 다시 늘려주고, 여기서 나온 값과 skip_input을 채널 레벨에서 합쳐 ouput으로 사용합니다.

그래서 Generator 아키텍처를 보시면, Down-sampling을 쭉 진행해서 512x1x1 사이즈로 만들고, 이제 Up-sampling을 해주는데, 여기서는 Skip-Connection을 사용하고, 아까 skip-connection은 채널 방향으로 쌓아준다고 했기 때문에, 여기서부터는 출력 채널의 사이즈가 입력 채널의 사이즈의 2배가 됩니다. 실제로 forward 연산 부분 보시면, encoder는 1개를, decoder는 skip-connection까지 2개를 input으로 받는 것을 보실 수 있습니다. 이러한 방식으로 Generator가 이미지를 생성합니다.
Discriminator Architecture: Patch GAN
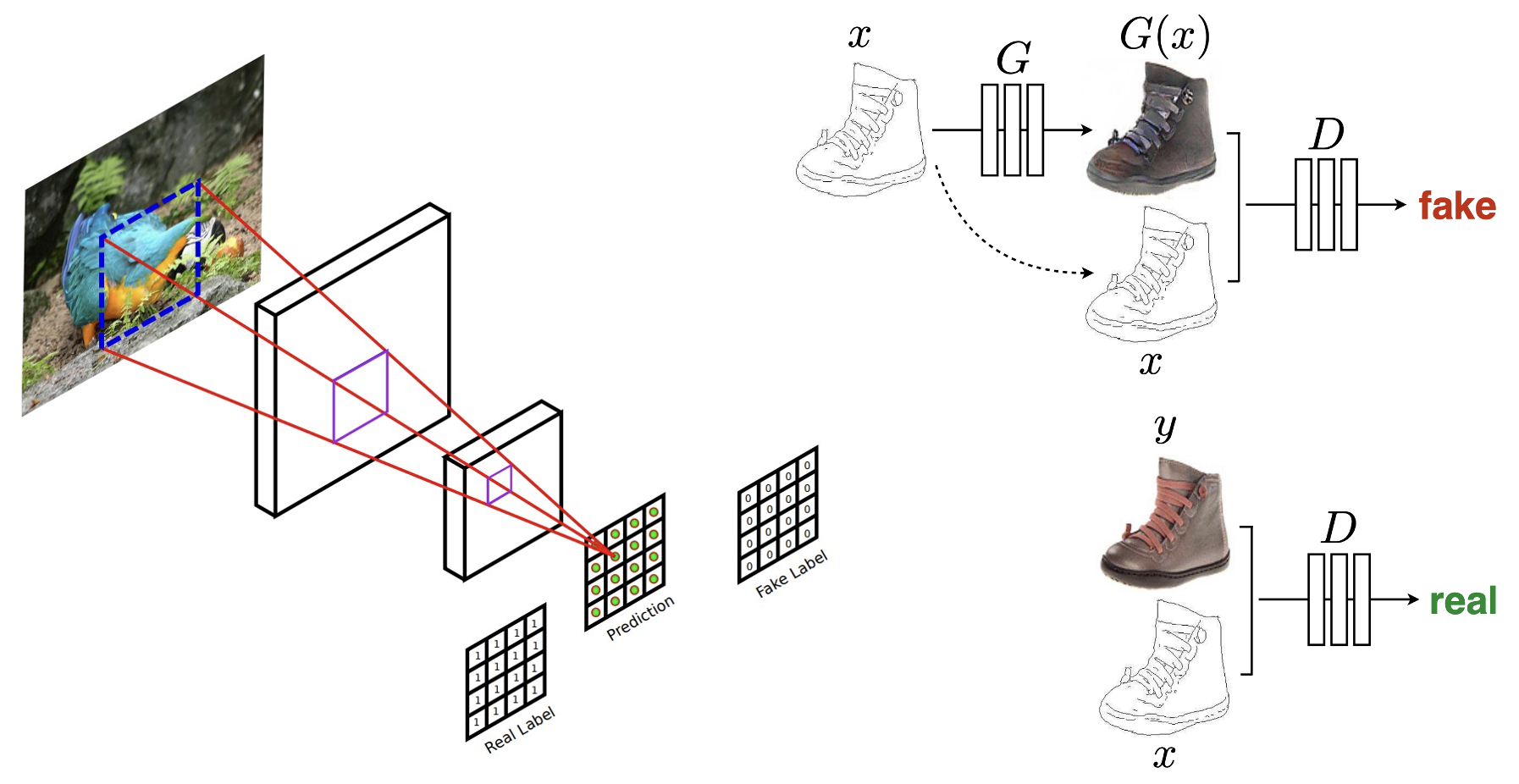
다음으로는 Discriminator인데요. 이 앞에서, Generator는 cGAN 뿐만 아니라, L1 loss를 추가적으로 이용함으로써 low frequency 이미지를 잘 구현해낸다고 했습니다. 그래서 저자들은 Discriminator을 통해 high frequency 부분을 잘 잡아내도록 설계를 합니다. 결국, 이미지 속에 들어있는 물체의 경계를 잘 잡아내겠다는 것인데, 그 방식으로 Patch GAN을 사용을 했습니다. 방법은 간단합니다. 그냥 이미지를 NxN Patch로 조각내서 판별합니다. 뭐 당연히 경계를 잡아내는 데에 있어서는 작은 조각으로 나눴을 때 더 정확도가 올라가겠죠?

그래서 여기 실제 코드를 보시면, 우리가 Discriminator에서도 condition 이미지를 함께 입력했죠. 여기서도 두개의 input image를 받아서 합친 뒤에, 이것을 모델에 넣습니다. 그래서 최종 1x16x16 feature map이 출력되는데, 16x16 patch로 나눈 것을 볼 수 있습니다. 이렇게 나눠준 이미지로 discriminator을 학습시킵니다.

Patch 개수로는 무작정 많이 나간다고 좋아지는 것이 아니고, 이렇게 70x70 정도가 적당하다고 합니다.
코드 출처
https://github.com/ndb796/Deep-Learning-Paper-Review-and-Practice
GitHub - ndb796/Deep-Learning-Paper-Review-and-Practice: 꼼꼼한 딥러닝 논문 리뷰와 코드 실습
꼼꼼한 딥러닝 논문 리뷰와 코드 실습. Contribute to ndb796/Deep-Learning-Paper-Review-and-Practice development by creating an account on GitHub.
github.com

