*본 내용은 논문의 상세한 분석이 아닌, 간단한 복기용 정리입니다.
DCGAN은 2016년에 ICLR에서 다루어졌고, Facebook Research가 발표했습니다.
Development Process of GAN
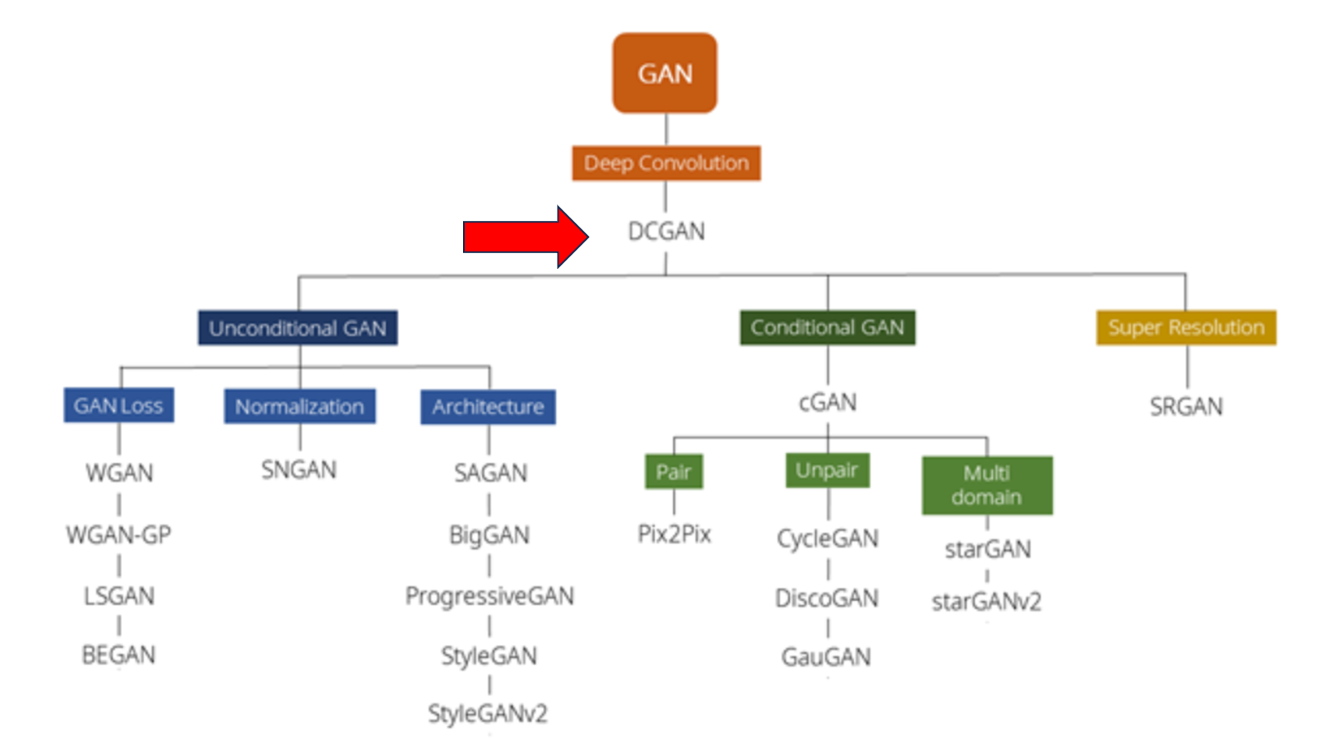
이 그림은 GAN의 발전 과정에 대한 그림입니다. 보시면 GAN의 개념이 나온 뒤에 안정성 문제가 심각해 응용이 많이 생길 수 없었는데요. GAN에 Convolution 개념을 도입하여 DCGAN을 탄생시킴으로써 GAN이 폭발적으로 성장할 수 있게 되었습니다. 기본적으로 여기 보이시는 모델 거의 모두 Convolution을 기반으로 하고 있고요. 여기서 이제 저번 시간에 발표한 Conditional 조건부 개념이 들어가냐, 들어가지 않냐, 등의 기준으로 GAN의 종류를 나눈 표입니다.
Why DCGAN?

아래 보이는 수식은 Vanilla GAN의 Objective Function입니다.
GAN은 태생적으로 불안정성을 항상 가지고 있습니다. 우선 minimax 문제를 풀어야 했습니다. 판별자는 D_Loss를 최대한 높히고(maximize), 생성자는 G_Loss를 최대한 낮추는(minimize) 방향으로 학습되어야 했습니다. 이렇게 되면 판별자와 생성자가 고루 학습이 되어야하는데, 판별자가 생성자를 압도하는 경우가 자주 발생하고, 성능이 안정적으로 수렴할 수 없습니다.

이제 DCGAN의 구조에 대해서 보겠습니다. 이 논문에서는 DCGAN의 구현에 대해서 그냥 바로 다음과 같이 가이드라인을 줬는데요. 논문에서 “Extensive research and testing을 통해서 최신 변화를 계속 적용하면서 찾았다.” 이렇게만 나와 있었습니다. (노가다를 많이 해서 찾은 결과인 것 같습니다.)
- 첫번째는 Pooling layer 대신 stride와 fractional stride Convolution layer을 사용하는 것.
- 두번째는 Generator와 Discriminator에 Batch Normalization을 사용하는 것.
- 세번째는 Fully Connected Layer 사용하지 않기
- 네번째는 Generator엔 ReLU 사용하고, 마지막에는 하이퍼볼릭 탄젠트 (Tanh) 사용할 것
- 마지막으로는 Discriminator에서는 Leaky ReLU를 사용하고, 마지막에는 Sigmoid 사용할 것 입니다.
이 해당 가이드라인을 기반으로 DCGAN의 Generator을 구현해보겠습니다.
구현에 앞서 용어 설명부터 하겠습니다.
(Fractional) Strided Convolution

여기서 먼저 아까 1번에서 언급한, strided convolution에 대해서 보겠습니다. Strided convolution은 우리가 알고 있는 일반적인 Convolution입니다. 이 gif에서는 3x3 필터로 패딩이 하나인 이미지를 2만큼의 stride로 합성곱 연산을 합니다. Output으로 나온 이미지는 더 작아집니다.
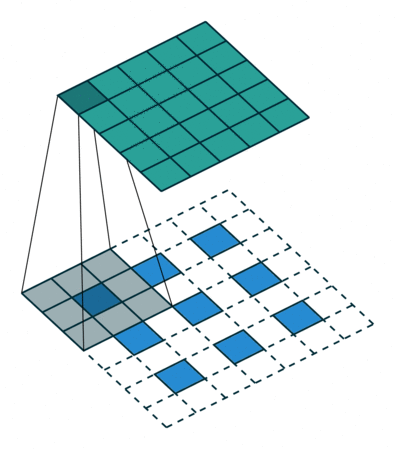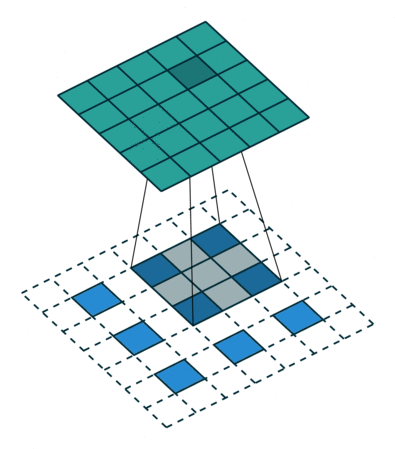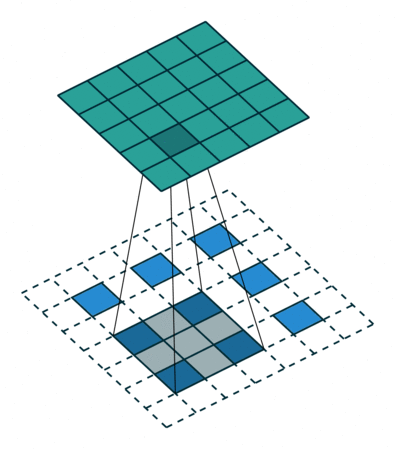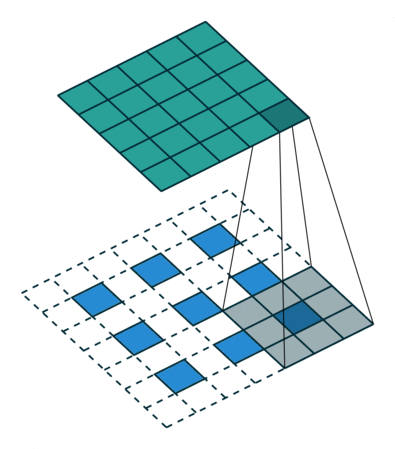
Fractional Strided Convolution은 반대로 원래의 3x3 이미지에서 하나의 픽셀당 패딩을 모두 채워 넣은 뒤에 (이걸 fraction 분할 이라고 부르는 듯) 합성곱 연산을 하면 output으로 나온 이미지는 5x5로 더 커지는 것을 볼 수 있습니다. 그래서, 벡터를 받아 이미지를 생성해야 하는 Generator는 Fractional strided convolution을 사용하고, 이미지를 받아 스칼라 값을 내보내는 Discriminator는 크기를 줄여주는 Strided Convolution을 사용합니다.
용어를 하나 짚고 가자면, 이 Fractional strided Convolution은 Convolution을 반대로 수행하는 것 같잖아요? 그래서 Deconvolution이라고도 불리는데요. 이 Deconvolution이라는 이름이 문제가 있어서, 보통 Transpose Convolution 이라고 부른다고 합니다. 뒤에 나오는 코드에서도 ConvTranspose로 들어가 있습니다.
우선 코드에서 사용되는 기본 설정값들은 다음과 같습니다.
# 데이터셋의 경로
dataroot = "data/celeba"
# dataloader에서 사용할 쓰레드 수
workers = 2
# 배치 크기
batch_size = 128
# 이미지의 크기입니다. 모든 이미지를 변환하여 64로 크기가 통일됩니다.
image_size = 64
# 이미지의 채널 수로, RGB 이미지이기 때문에 3으로 설정합니다.
nc = 3
# 잠재공간 벡터의 크기 (예. 생성자의 입력값 크기)
nz = 100
# 생성자를 통과하는 특징 데이터들의 채널 크기
ngf = 64
# 구분자를 통과하는 특징 데이터들의 채널 크기
ndf = 64
# 학습할 에폭 수
num_epochs = 5
# 옵티마이저의 학습률
lr = 0.0002
# Adam 옵티마이저의 beta1 하이퍼파라미터
beta1 = 0.5
# 사용가능한 gpu 번호. CPU를 사용해야 하는경우 0으로 설정하세요
ngpu = 1
먼저 Generator부터 보겠습니다.
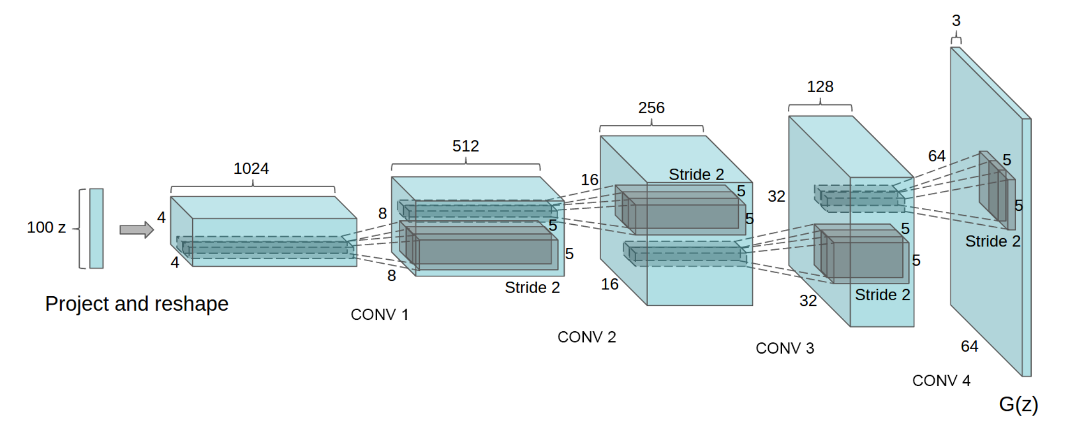
Generator의 구조와 코드는 다음과 같습니다.
class Generator(nn.Module):
def __init__(self, ngpu):
super(Generator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# 입력데이터 Z가 가장 처음 통과하는 전치 합성곱 계층입니다.
nn.ConvTranspose2d( nz, ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
# 위의 계층을 통과한 데이터의 크기. ``(ngf*8) x 4 x 4``
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# 위의 계층을 통과한 데이터의 크기. ``(ngf*4) x 8 x 8``
nn.ConvTranspose2d( ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
# 위의 계층을 통과한 데이터의 크기. ``(ngf*2) x 16 x 16``
nn.ConvTranspose2d( ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
# 위의 계층을 통과한 데이터의 크기. ``(ngf) x 32 x 32``
nn.ConvTranspose2d( ngf, nc, 4, 2, 1, bias=False),
nn.Tanh()
# 위의 계층을 통과한 데이터의 크기. ``(nc) x 64 x 64``
)
def forward(self, input):
return self.main(input)
100개의 노이즈 벡터로부터 4x4 그리고 1024개의 채널을 가지는 feature을 가지는 Convolution layer을 만듭니다. 이제 채널사이즈는 반씩 줄이고, x,y dimension이 두배씩 커지니까 stride도 2로 설정합니다. 이렇게 같은 과정을 4번 더 거쳐, 마지막으로는 RGB값을 가지는 3x64x64 이미지를 생성합니다.
ConvTranspose2d는 ( input채널수, output채널수, kernel사이즈, stride사이즈, padding) 순서로 되어 있습니다.
이제 Discriminator입니다.
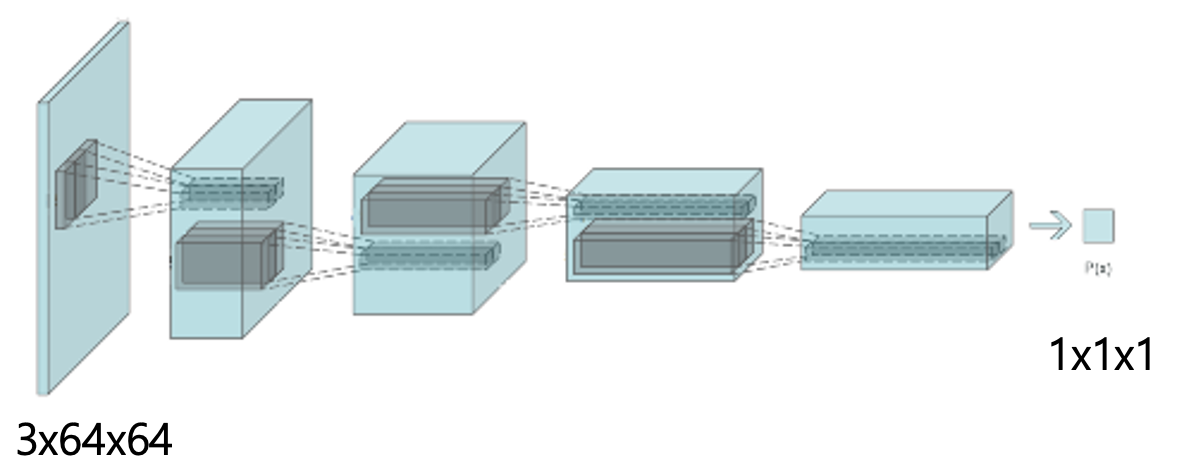
Discriminator의 구조와 코드는 다음과 같습니다.
class Discriminator(nn.Module):
def __init__(self, ngpu):
super(Discriminator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# 입력 데이터의 크기는 ``(nc) x 64 x 64`` 입니다
nn.Conv2d(nc, ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# 위의 계층을 통과한 데이터의 크기. ``(ndf) x 32 x 32``
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# 위의 계층을 통과한 데이터의 크기. ``(ndf*2) x 16 x 16``
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# 위의 계층을 통과한 데이터의 크기. ``(ndf*4) x 8 x 8``
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# 위의 계층을 통과한 데이터의 크기. ``(ndf*8) x 4 x 4``
nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, input):
return self.main(input)Generator가 1x1x100의 인풋에서 3x64x64로 갔다면, Discriminator은 반대로 이미지 3x64x64를 받아 스칼라 값인 1x1x1로 갑니다. 이 나온 스칼라 값이 0.5보다 크면 Real image, 0.5보다 작으면 Fake image로 판단합니다. 여기서는 일반적인 Convolution을 통해 feature map 사이즈를 다시 줄여주므로 그냥 Conv2d를 사용한 것을 볼 수 있습니다. 아까 가이드라인에서 나와 있었듯이, 아까 Generator에서는 ReLU, Discriminator에서는 Leaky ReLU를 사용했습니다. 이런 식으로 DCGAN의 구조는 이루어져 있습니다.
More Goals of DCGAN

아까 앞서서 DCGAN의 목표가 GAN의 안정성 문제라고 말씀드렸는데, DCGAN은 목표하는 바가 더 있습니다. Generator가 이미지를 외워서 보여주는 것이 아니라는 것을 확인시켜주어야 합니다. Generator의 input은 우리가 latent space라는 noise 분포에서 뽑았잖아요? 그런데 이때 만약에 Memorization이 일어나서 Generator가 유의미한 특징을 학습해서 이미지를 만드는 것이 아니라, overfitting이 일어나서, 노이즈 벡터 z와 이미지 간의 1:1 mapping을 해버린다고 가정해보겠습니다. 그러면, 이 noise 분포 안에서 z 값을 뽑을 때, z값을 하나씩 옮겨가며 (옆으로 이동하며) Generator로 이미지를 만들었을 때, 생성자 입장에서 굳이 출력 이미지를 부드럽게 연결할 필요가 없을 것입니다. 그냥 하나의 z에 하나의 이미지가 연결만 되면 되니까, 들쑥날쑥한 이미지가 학습될 수 있습니다. 이러한 문제를 DCGAN 구조가 해결합니다.
두번째로는 Neural Network의 고질적 문제인 black box 문제를 얼추 해결합니다. 사실 제가 너무 오래전의 논문들만 보다 보니까, 최근에도 이런 것들이 문제가 되는지는 사실 잘 모르겠습니다. 근데 2014년부터 2016년 이 당시에는 많은 논문이 문제에 집중했었다고 하네요. 저희가 아까 봤던 Deconvolution을 이용해서 이 Black box 문제를 해결하려는 여러 시도가 있었는데, 쉽지 않았다고 합니다. 그런데 이 DCGAN이 이 문제를 어느정도 해결하는 모습을 보여줍니다.
Result: Walking in the latent space

먼저 latent space에서 walking 하는 결과부터 보겠습니다. 여기 박스 쳐져 있는 곳을 보시면, 벽이 있던 곳에서 부드럽게 창문으로 이미지가 바뀝니다. Memorization이 이루어져 1:1 mapping 때문에 들쑥날쑥하지 않고, 학습을 통해 부드러운 결과를 나타낸 것을 볼 수 있습니다.
Result: Visualizing the Discriminator Features

CNN을 사용하게 되면서 black box라는 Neural Network의 고질적 문제도 같이 발생했는데, Back propagation 과정에서 이 정보를 저장을 하고, visualization을 해서 generator가 이미지를 생성을 할 때, 어느 정도의 기준을 가지고 이미지를 생성을 했는지 보여줍니다.
왼쪽 그림은 그냥 랜덤한 filter 그림입니다. 보시면 여기는 그냥 포괄적인 그림만 있지 딱히 하나의 구조를 특정할 수 없지만, 오른쪽에 학습된 필터들은 잘 안 보이지만 커튼, 침대, 창문 등등 이런 구조로 나누어, feature의 어떤 부분의 특징을 학습하여 이미지를 생성해냈는지 보여줍니다.
Result: Dropping out filters

학습에 사용한 filter도 눈으로 확인을 했으니까, 이젠 그 filter을 drop out을 시켜서, 이미지에서 해당 특징이 사라지게도 할 수 있습니다. 박스 친 곳을 보시면, 창문이 사라집니다. “학습” 뿐만이 아니라 “망각” 또한 가능하게 해서 역설적으로 학습이 잘 되었다는 것을 보여주기도 합니다.
코드는 다음을 참고했습니다.
https://github.com/PyTorchKorea/tutorials-kr/blob/master/beginner_source/dcgan_faces_tutorial.py

