*본 내용은 논문의 상세한 분석이 아닌, 간단한 복기용 정리입니다.

Method

SENet은 크게 Squeeze와 Excitation 과정으로 나누어집니다.
- Squeeze: 쥐어짜고,
- Excitation: 활성화하는 네트워크입니다.
대략적인 과정은 맨처음 input 이미지에서 conv 연산을 통해 feature map을 생성하고, 그 다음 squeeze작업을 통해 쥐어짜서, 여기서 활성화해서 마지막에 곱해주는 과정입니다.

첫번째 squeeze 과정에서는, 저번 시간에 설명한 Global Average Pooling을 진행합니다.
여러 채널로 되어있는 여기 feature map에서 각 한 채널당 평균을 내서 하나의 값으로 이루어진 채널을 구성합니다.
여기 보이시는 것처럼 채널만 여러개로 남겨둔 채 1x1xC 차원으로 바꿔주는 작업을 Squeeze라고 합니다.
여기 보이시는 Squeeze 공식은 Global Average Pooling을 하는 수식입니다.
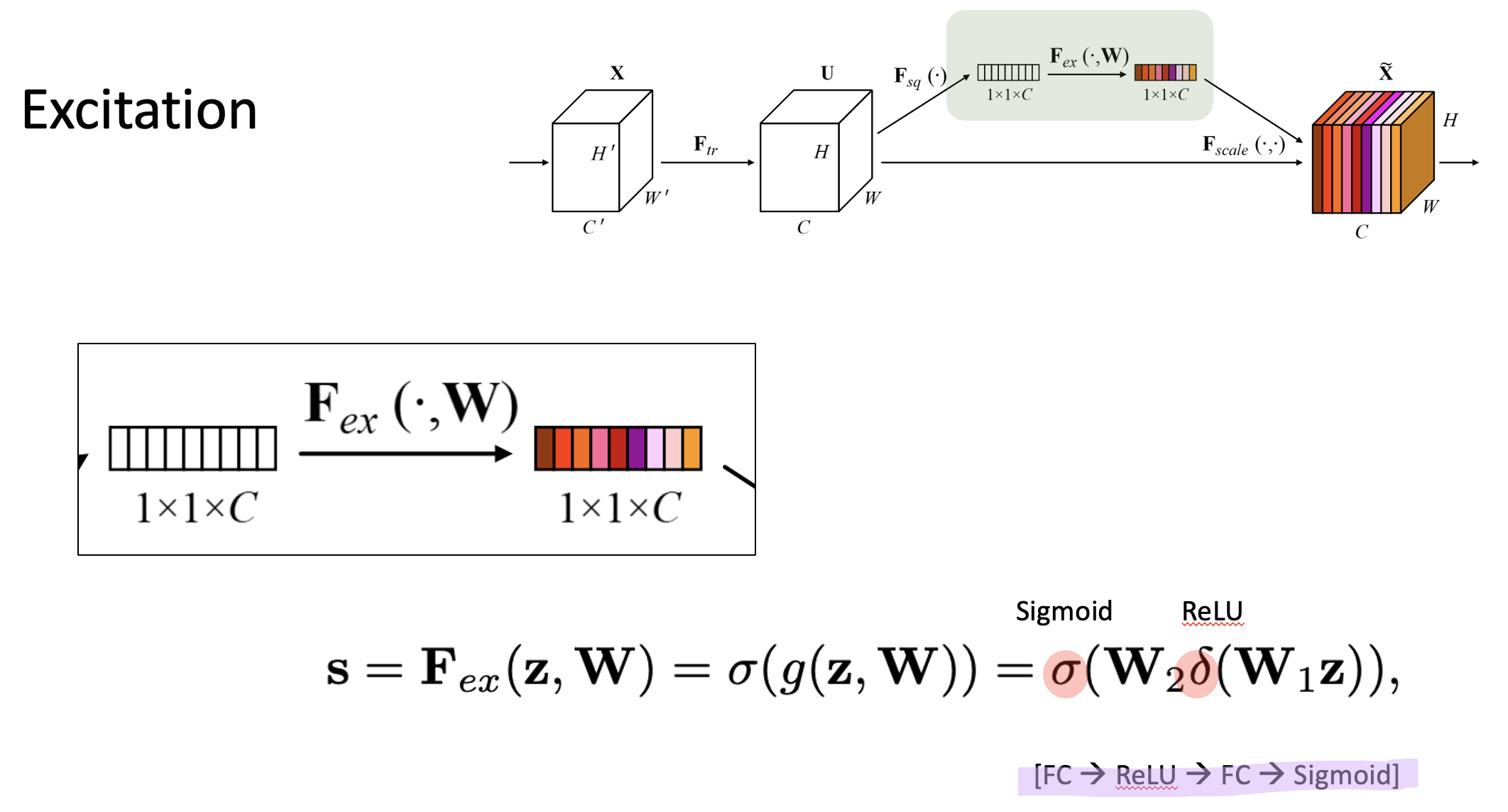
그 다음 활성화를 하는 Excitation과정에서는, 여기 보이시는 델타 표시가 ReLU를 의미합니다. 그리고, 여기 보이시는 시그마가 시그모이드 기호입니다.
위 수식에서 보이다시피, Global Average Pooling의 아웃풋으로 나온 z, 즉 1x1xC 이 vector을
- Fully connected layer에 넣어
- Weight를 곱해주고,
- ReLU 하고,
- 그 다음 Weight를 다시 곱해서
- 마지막으로 sigmoid를 계산
해주는 과정을 Excitation이라고 합니다.
이 과정을 거치면, 이전 input에서 1x1xC로 평탄화 해놓은 값에서, 각 채널별로 중요한 수치를 뽑아냅니다. 마지막에 sigmoid를 거쳤기 때문에 이 각 채널간의 중요도인 채널 어텐션이 0~1 사이로 모두 배정됩니다.

그 다음 맨 처음의 feature map 과 excitation 과정을 거쳐 나온 벡터를 곱해줍니다.
각 한 채널당 하나씩 곱해주면, 맨 처음의 feature map에 중요도가 부여가 됩니다.
이렇게 처음의 Feature map에 중요도를 부여해준 값이 이 마지막 output feature map입니다.
이 과정에서도 bottle neck 구조가 활용됩니다. parameter 개수를 늘리지 않을 수 있고, 첫번째 Fully connected layer에서 input layer node를 받는 hidden layer node 수를 줄여 일반화, generalization을 해줄 수 있습니다.

여기 왼쪽은 Inception 모듈이 있는 GoogleNet이고, 오른쪽은 ResNet입니다.
보이는 것처럼 ResNet에서 Skip conncection 사이에 SE 구조가 들어와 있습니다.
SENet의 구조는 SE Block이라고 불리면서 어떤 모델이든지 부착하여 성능을 향상할 수 있습니다.
'AI 논문 리뷰(AI Paper Review) > 컴퓨터비전(Computer Vision)' 카테고리의 다른 글
| [논문 정리] Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction w (0) | 2023.09.01 |
|---|---|
| [논문정리] ECA-Net: Efficient Channel Attention for Deep Convolutinoal Neural Networ (0) | 2023.09.01 |
| [논문정리] CSPNet 개념 정리 (0) | 2023.09.01 |
| [논문정리] DenseNet 개념 정리 (0) | 2023.09.01 |
| [논문정리] ResNet 개념 정리 (0) | 2023.09.01 |



