*본 내용은 논문의 상세한 분석이 아닌, 간단한 복기용 정리입니다.
CSPNet은 DenseNet을 그대로 차용해서 약간 형태를 바꾼 모델이라, DenseNet 부분과 많은 부분이 겹칩니다.
https://stevenkim1217.tistory.com/entry/DenseNet-%EA%B0%9C%EB%85%90-%EC%A0%95%EB%A6%AC
DenseNet 개념 정리
*본 내용은 논문의 상세한 분석이 아닌, 간단한 복기용 정리입니다. DenseNet은 ResNet의 Architecture에서 발전했습니다. ResNet 문서는 이전 게시물을 참조하세요. https://stevenkim1217.tistory.com/entry/ResNet-%EA%
stevenkim1217.tistory.com
CSPNet은 앞서 설명한 기존의 SOTA인 ResNet과 DenseNet의 연산량을 가볍게 줄여주는 경량화에 초점을 맞췄습니다.
DenseNet에서 연산이 너무 무거워서 연산량을 줄여주는 방법론으로 제안된 게 CSPNet입니다.
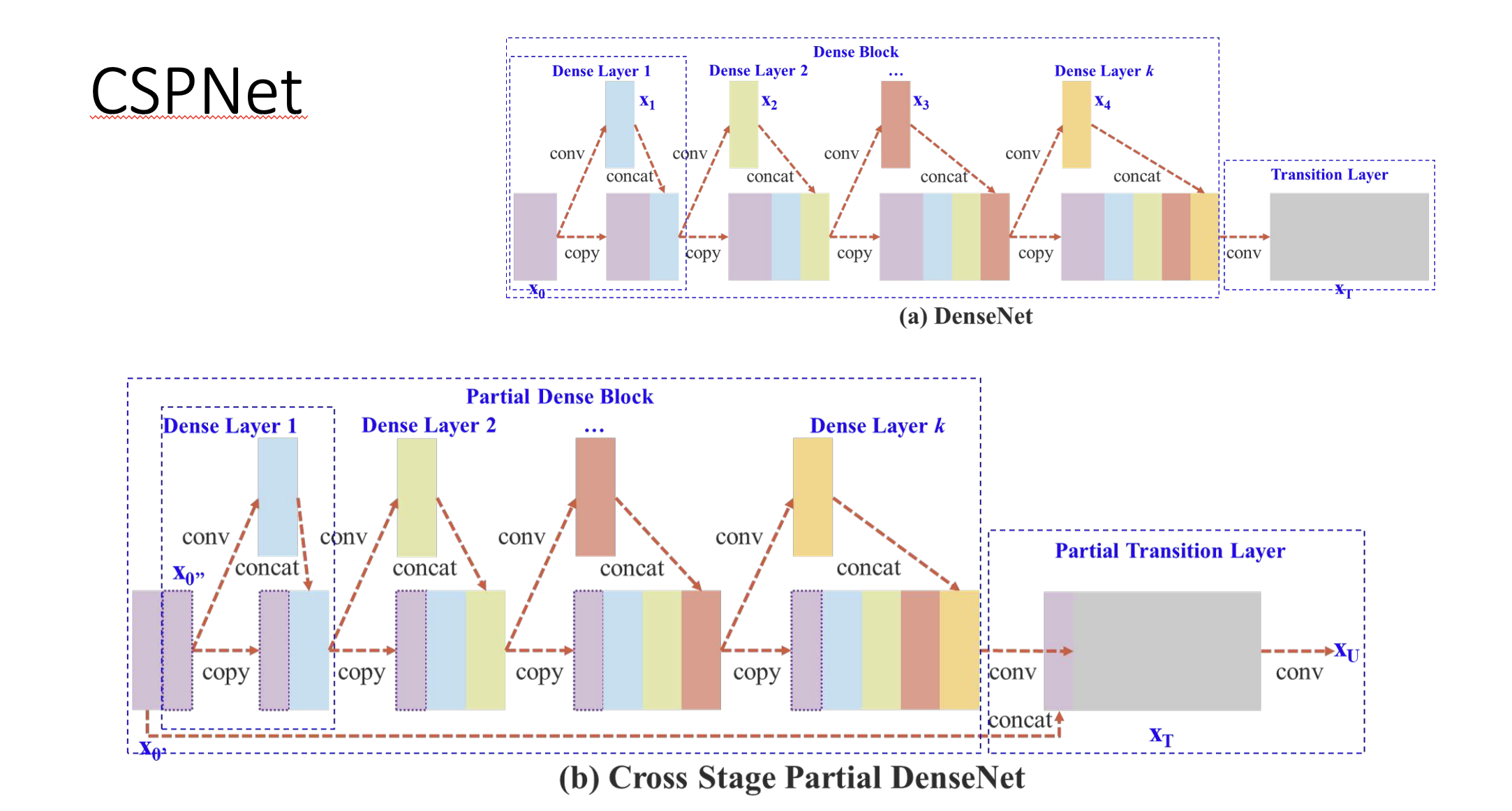
CSPNet의 구조는 위와 같습니다.
맨 처음의 layer에서 feature map을 두 갈래로 갈라줍니다.
그 다음에 쪼갠 것 중 하나만 convolution 연산을 진행하고, 나머지 하나는 그냥 마지막에 Cross-stage라고 불리는 곳에서 이 둘을 합치기만 해주는 방식으로 진행됩니다.
Cross Stage Partial DenseNet
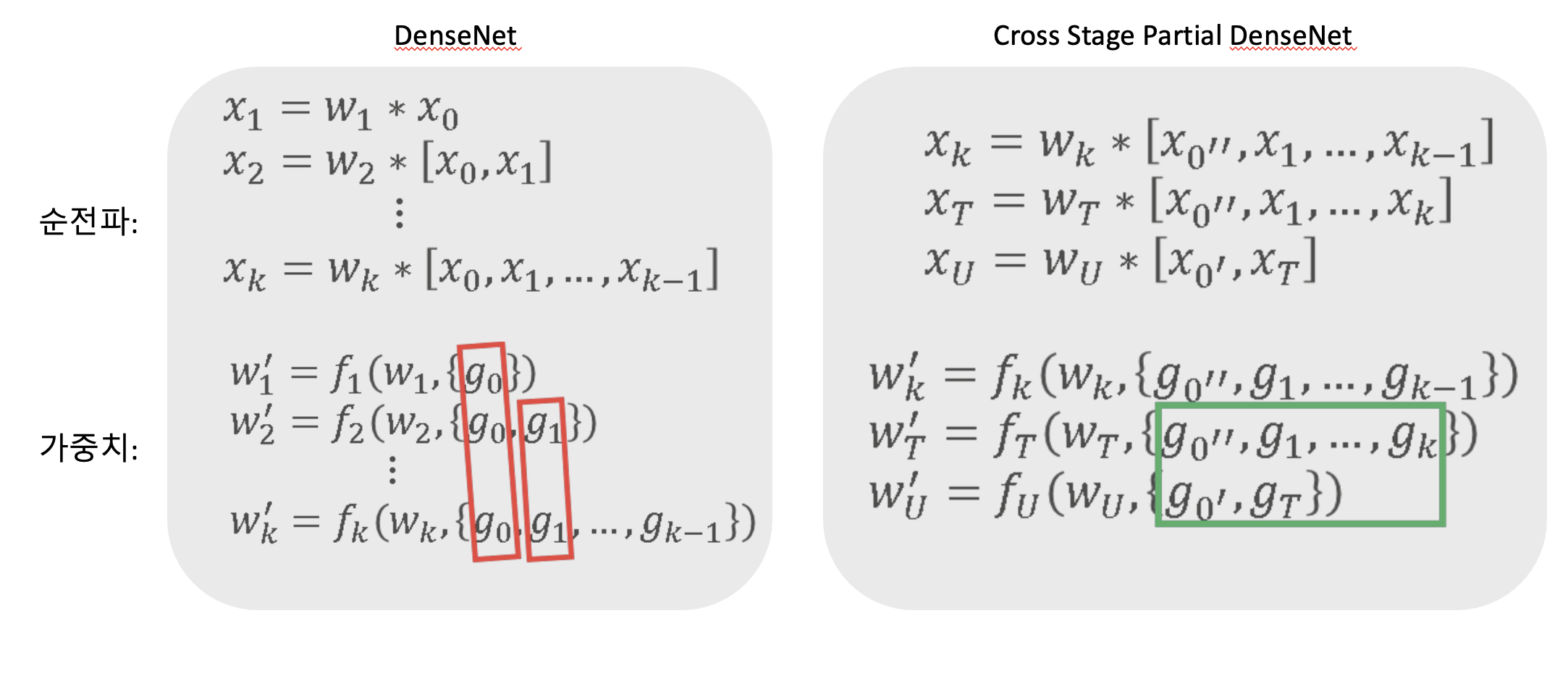
기존의 DenseNet의 가중치 구하는 공식의 빨간색 박스를 보시면, 가중치를 갱신하는 과정에서gradient 정보가 반복해서 사용됩니다.
그래서 이 논문에서 제시하는 Cross Stage Partial DenseNet은 어떤 방법으로 해결했는지 보겠습니다.
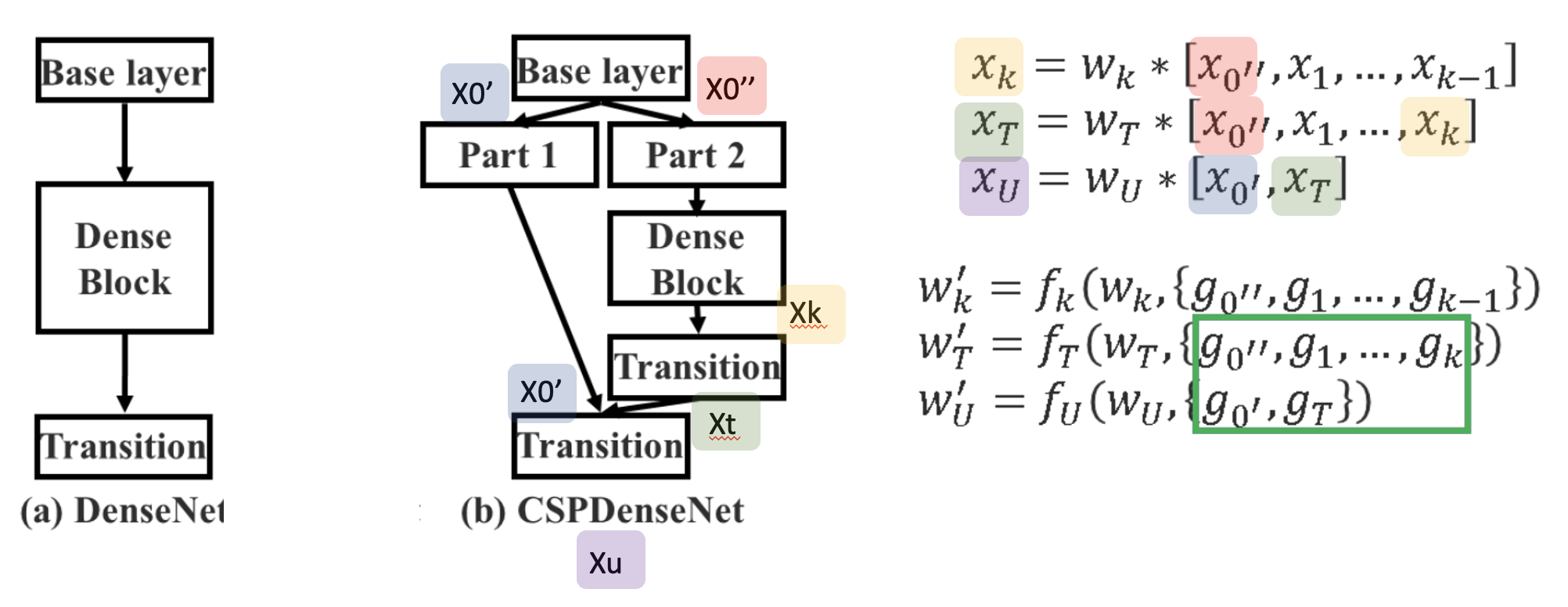
- base layer의 출력값인 X0' 값이 part1이 되고, X0"가 part2가 됩니다.
- 그럼 X0"는 Denseblock을 통과하며 여러 가중치들을 지나 X_k가 되었고 마지막 Transition layer를 통해 X_t가 됩니다.
- 그 후 stage의 마지막 단계에서, part1의 X0'와 part2에서 Denseblock을 지나온 X_t가 만나 X_u가 됩니다.
- 따라서 dense layer를 통과하지 않는 x'0의 gradient 정보는 복사되지 않습니다.
- 역전파 단계 역시 마찬가지로 반대로 이동하면서 가중치를 업데이트합니다.
Fusion First vs Fusion Last
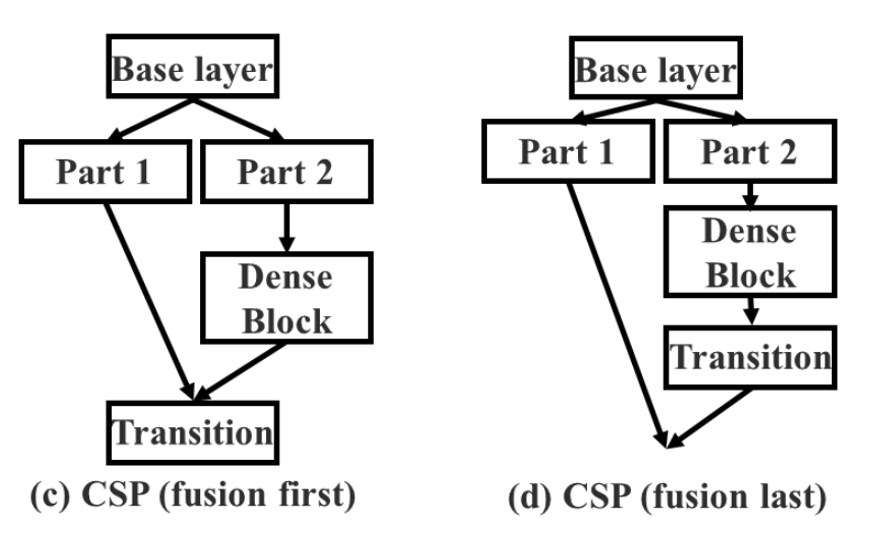
처음에 나눈 두 값을 합치는 걸 Fusion이라고 하는데요. 이 fusion을 언제 하냐에 따라서 성능이 또 차이가 납니다.
Fusion First는 두 파트에서 생성된 feature를 먼저 합친 뒤에 transition을 진행합니다. 이러면 많은 양의 gradient가 재사용됩니다. 상대적으로 비효율적인 것이죠.
Fusion Last가 제가 앞에서 설명한 CSPNet 모델인데요, dense block에서 나온 feature map은 transition layer를 거친 후에 base layer에서 나온 feature map과 합쳐집니다. 이러면, 앞서 보여드린 것처럼 gradient flow가 분할되었기 때문에 gradient가 재사용되지 않습니다.
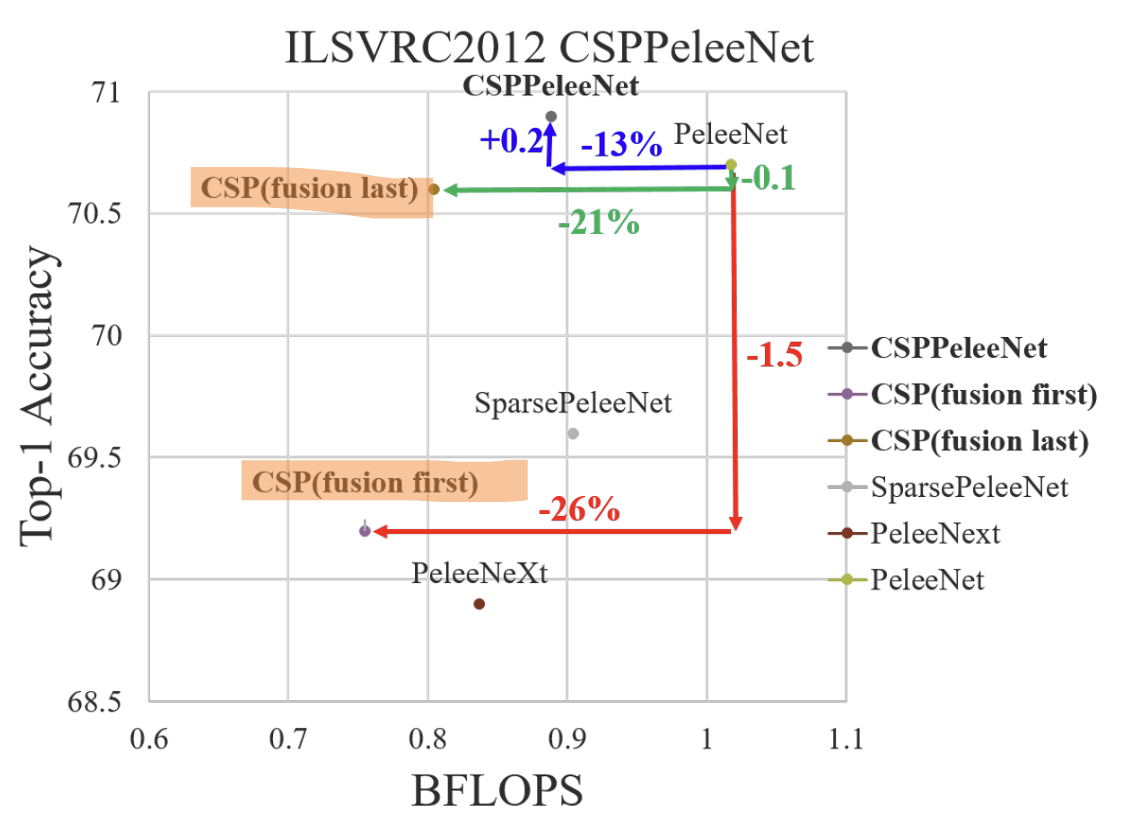
여기 보시면 fusion last가 first보다 높은 정확도를 보이는 것을 볼 수 있습니다.

이 CSPNet이 연산량을 줄였다는 업적이 있는데요. 이 CSPNet이 주목받은 이유는 ResNet과 같은 이런 다른 유명 모델들에도 전부 적용할 수 있다는 점입니다. 앞의 Dense Block 자리에 다른 아키텍처 블록을 끼우면 됩니다.
'AI 논문 리뷰(AI Paper Review) > 컴퓨터비전(Computer Vision)' 카테고리의 다른 글
| [논문정리] ECA-Net: Efficient Channel Attention for Deep Convolutinoal Neural Networ (0) | 2023.09.01 |
|---|---|
| [논문정리] SENet: Squeeze and Excitation Networks (0) | 2023.09.01 |
| [논문정리] DenseNet 개념 정리 (0) | 2023.09.01 |
| [논문정리] ResNet 개념 정리 (0) | 2023.09.01 |
| [논문 정리] DeiT: Training data-efficient image transformers & distillation through attention (0) | 2023.09.01 |



