*본 내용은 논문의 상세한 분석이 아닌, 간단한 복기용 정리입니다.
Introduction
FPN이라고 부르는 Feature Pyramid Network 등 이전의 많은 논문에서 이 Pyramid 구조에 대해서 다뤘는데요.

이 Pyramid 구조는 여기 그림에서 보이는 것처럼 서로 다른 해상도의 feature map을 쌓아 올린 형태를 말합니다. 이 다양한 scale의 feature map을 모두 이용하여 segmentation을 수행합니다.

Receptive field는 기존 이미지에서 한 픽셀이 담당하는 범위를 말하는데요. 이렇게 pyramid 구조를 가지면, 깊이가 더 깊어질수록, feature map에서 한 픽셀이 담당하는 범위가 늘어나게 됩니다.
즉, 깊이가 깊어질수록 receptive field가 더 늘어나는 것입니다.
이번 논문에서 목적으로 가지는 Semantic Segmentation에서는 픽셀 단위로 image classification을 해야 하기 때문에, 이미지를 down-sampling을 거쳐서 계속 사이즈를 낮춰서, 정답에 가까운 결론을 내릴 수 있도록 하는 것이 필수적입니다.

그런데 ViT가 semantic segmentation과 같은 dense prediction에 한계를 가지는 이유는 앞서 설명한 이런 피라미드 구조가 dense prediction에서는 필수적인데, pyramid 모양처럼 위로 줄어드는 구조가 아니라, 수직으로 올라가는 columnar 구조를 가집니다.
이렇게 single-size scale로 task를 수행하기 때문에, 다양한 scale의 feature map을 출력하여 이용하는 segmentation task에 적합하지 못합니다.
ViT는 attention을 통해 classification을 수행하기 때문에, global한 feature를 추출한다는 장점은 있으나, dense prediction을 하기 위해 중요한 요소 중 하나인 multi-scale feature를 추출하지 못한다는 것입니다.
방금 말씀드렸는데, Vision Transformer은 attention 구조를 통해, 한 번에 이미지의 feature을 추출하기 때문에 global한 feature을 추출한다고 할 수 있습니다.
그러나 CNN은 filter를 통해 convolution 연산을 하기 때문에, 픽셀이 local한 receptive field를 가집니다.
Global한 feature을 추출하는 ViT의 장점을 Semantic Segmentation과 같은 Dense Prediction에 적용하기 위해 나온 대안이 지금 말씀드리는 Pyramid Vision Transformer입니다.
Background: Scale

PVT architecture을 설명하기에 앞서, scale과 resolution에 대해 말씀드리겠습니다.
Scale은 이미지 사이즈와 반비례 되는 개념인데요. 인식하고자 하는 개체를 Window 안에 얼마나 넣을 수 있냐, 즉 얼마나 잘 개체를 포함할 수 있냐에 대한 범위를 말합니다.
동일한 Window 사이즈를 가정한다고 했을 때, 이미지가 작아질수록 이 Window 안에 들어가고자 하는 고양이나 인형의 크기가 커집니다.인식하고자 하는 개체가 전부 포함될 수 있게 되므로 scale이 커진다고 할 수 있습니다.
Background: Resolution

다음은 해상도에 대한 설명입니다.
기본적인 CNN 모델은 Convolution과 Pooling을 거쳐 사이즈를 줄이고, 마지막에 Fully connected layer에서 task를 수행합니다.
이때 Pooling을 거치며 이미지의 사이즈를 계속해서 줄이기 때문에, 맨 처음 input 이미지에 가까운 feature map은 원본 이미지와 더 가깝고 더 자세하게 나와있기 때문에 높은 해상도라고 하는 것입니다.
그렇지만 해상도는 높아도 뽑아내고자 하는 특징을 feature map에서 잘 나타내지는 못하므로 low-level feature이라고 합니다.
연산을 거치고 더욱 깊어질수록 반대의 특성을 가진다고 생각해주시면 되겠습니다.
Method

이제 PVT의 구조에 대해 설명하겠습니다.
PVT는 총 4개의 stage로 구성되어 있으며, 각각 서로 다른 scale의 feature map을 생성합니다. 또한 모든 stage는 patch embedding layer와 Li Transformer encoder layer로 구성되어 있습니다.
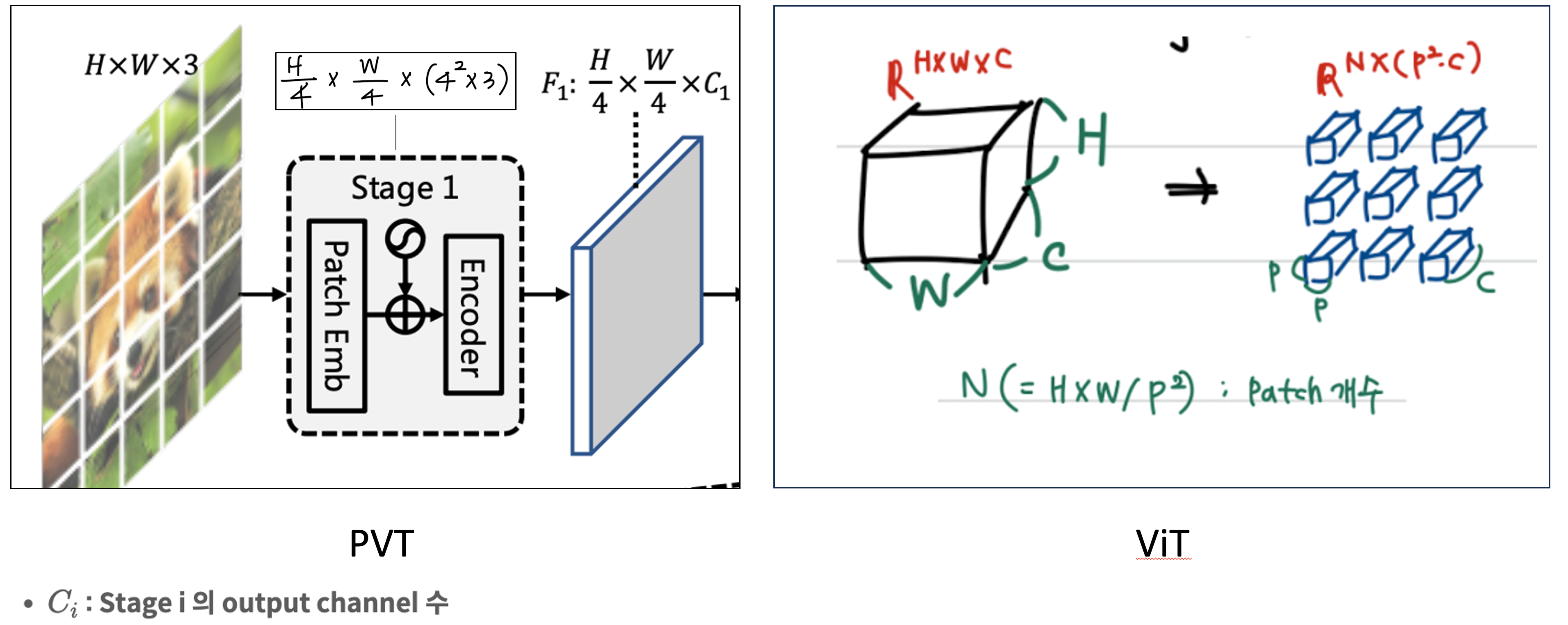
첫 번째 stage에는
- 우선, patch size를 4x4x3으로 설정합니다.
- Patch size가 4x4이기 때문에 맨 처음의 HxWx3 사이즈의 input 이미지가 HW/4^2 개의 patch로 나눠줍니다. 이때의 사이즈는 H/4 x W/4 x ( 4^2 x 3 )이 되겠죠?
- 이 patch들을 flatten하고, Linear projection으로 각 패치를 1차원으로 만드는 patch embedding을 수행하면, 여기 F1이라고 나와있는 size를 가집니다. 즉, 이 뒷부분을 C차원으로의 Projection을 통해서 싹 날려주는 것입니다.
기존 ViT에서도 Encoder에 들어가기 전에 한 번의 patch embedding은 거치기 때문에 여기까지는 기존의 ViT의 과정과 동일합니다.
(우측의 ViT 그림은 이해를 위해 첨부했습니다.)

I번째 Stage의 과정을 다시 한 번 보시면 위 그림과 같습니다.
Patch size만큼 input image를 먼저 분할하고, patch embedding으로 feature map의 사이즈를 H/P x W/P로 줄였죠.
즉, 해상도를 이전 i-1 layer에 비해 P만큼 줄여준 상태로 Transformer Encoder에 넣습니다.
그런데 PVT에서는 이 이후에 오는 모든 stage에서 계속 반복해서 Patch Embedding을 수행해줍니다.
이렇게 되면 stage를 거칠수록 feature map의 크기는 patch 사이즈에 비례하여 줄어듭니다. 이런 방식으로 Vision Transformer에 Pyramid 구조를 적용했습니다.
아까 Resolution에 대해서 설명하면서 Pyramid 구조를 가지는 CNN에서 input image에 가까울수록 feature map은 low level이고, Resolution은 높아진다고 했습니다.
즉, 우리가 ViT에 Pyramid 구조를 차용하려면, ViT에서도 동일하게 낮은 층에서 고해상도의 feature map을 다뤄야 합니다. 그런데, attention은 아시다시피 아주 큰 연산량을 요구합니다.
그래서 이에 대한 해결책으로 기존의 attention 모듈 대신 새로운 attention을 제안합니다.
Spatial-Reduction Attention (SRA)

ViT의 Multi Head Attention 대신에 Spatial Reduction Attention을 본 논문에서 제안합니다.
SRA도 MHA와 마찬가지로 patch embedding이 된 벡터를 Query, Key, Value로 나누어 attention에 넣는 구조는 동일합니다.
그런데, 오른쪽 그림을 보시면, SRA의 경우 Spatial Reduction을 거쳐서 나오면 K와 V의 해상도가 감소된 상태로, 마지막에 Query와 연산되는 것을 볼 수 있습니다.
이 과정을 나타낸 수식은 아래와 같습니다.

SRA 과정에 대한 수식은 위 그림과 같습니다.
아래에서 기존 ViT의 방식과 비교하며 설명하겠습니다.

SRA의 1번 식은 맨 윗부분에서 MHA를 수행해주는 과정으로, 이전과 동일합니다.
- Multi head를 concate 해주고
- W0를 곱해줍니다.
- 또, 맨 아래에 상자에 보이시는 것처럼 기존의 transformer 방식에서 Query, Key, Value를 Linear Projection 해주잖아요? RSA에서도 그것과 동일하게, Linear projection을 수행합니다.
그런데, 이제 SRA의 (2)번을 보시면, 기존 ViT 방식과 다르게 Key와 Value에 SR이 적용되었는데요. 이 SR은 아래 (3)번의 수식을 적용한 것입니다.

그림 "SRA-1"의 Reshape 안에 x 콤마 Ri라고 되어 있는데요. 이건 input sequence인 x에 대해서, Reduction ratio인 R_i를 이용해 다음과 같이 Reshape하는 것을 말합니다.
이후,
- (2)번의 Linear Projection 가중치 Ws를 곱해준 다음
- layer normalization 해주면,
오른쪽 그림에서 SR을 빠져나온 저 Shape를 가지게 됩니다.
이렇게 R_i만큼 해상도가 감소된 Key와 Value에 대해, 각 head인 di 차원으로 projection 한 후에 attention을 수행하면, "그림 SRA-1"의 마지막 (4)번 식과 같습니다.
Key와 Value의 정보는 Ri^2 만큼 줄이고, 반면에 구하고자 하는 정보인 Query의 해상도는 유지하기 때문에, 성능 저하 없이 계산 비용을 크게 감소시켰습니다.
PVT는, attention을 통해
- 항상 global receptive field를 생성한다는 ViT의 장점과
- pyramid 구조를
통합시켜, object detection, segmentation에 적합한 모델을 만들었습니다.
Experiment

이 PVT 모델이 애초에 detection과 segmentation을 위해 개발되었기 때문에, Image Classification에 적합한 모델은 아닌데도 불구하고
ImageNet dataset 기반으로 PVT가 CNN backbone과 Transformer 기반 모델에 비해 더 좋은 성능을 보였고,
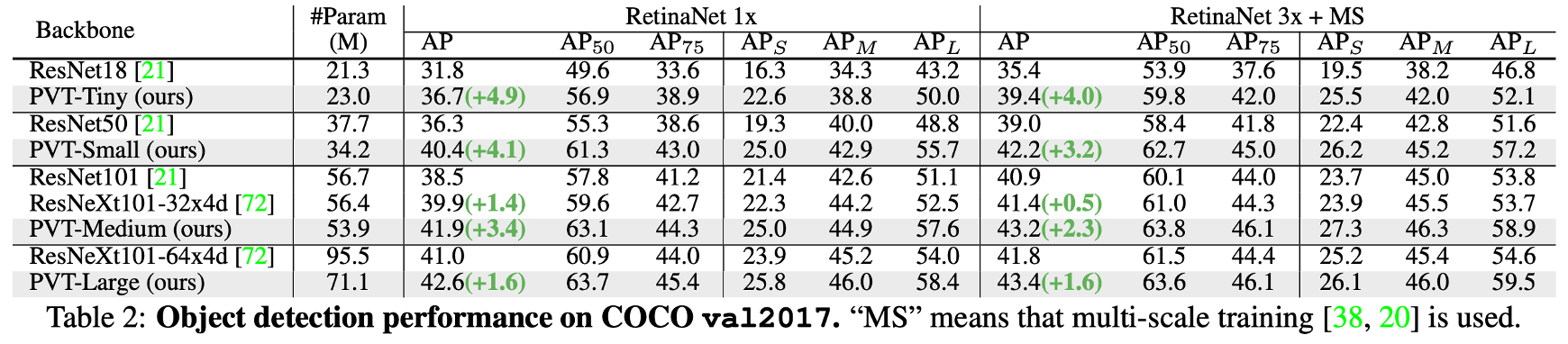

Object Detection과 Semantic Segmentation에서도 기존 CNN backbone에 비해서 유사한 parameter 수로 일관되게 좋은 성능을 보였습니다.
'AI 논문 리뷰(AI Paper Review) > 컴퓨터비전(Computer Vision)' 카테고리의 다른 글
| [논문정리] GhostNet: More Features from Cheap Operations (1) | 2023.09.01 |
|---|---|
| [논문정리] MobileNets: Convolutional Neural Networks for Mobile Vision Applications (0) | 2023.09.01 |
| [논문정리] ECA-Net: Efficient Channel Attention for Deep Convolutinoal Neural Networ (0) | 2023.09.01 |
| [논문정리] SENet: Squeeze and Excitation Networks (0) | 2023.09.01 |
| [논문정리] CSPNet 개념 정리 (0) | 2023.09.01 |



