*본 내용은 논문의 상세한 분석이 아닌, 간단한 복기용 정리입니다.
GhostNet의 기초가 되는 MobileNet에 대한 설명은 이전 게시물을 참조해주세요.
[논문정리] MobileNets: Convolutional Neural Networks for Mobile Vision Applications
*본 내용은 논문의 상세한 분석이 아닌, 간단한 복기용 정리입니다. Introduction MobileNet의 핵심 아이디어는 Depthwise Separable Convolution입니다. 이 개념은 Depthwise Convolution과 Pointwise Convolution을 조합하
stevenkim1217.tistory.com
Introduction

위 그림은 GhostNet의 기초가 되는 MobileNet의 구조입니다.
- 맨 처음에 Standard 3x3 Conv 연산을 거치고
- Depthwise(DW) Conv와 Pointwise(1x1) Conv를 반복합니다.
- 마지막에 Fully Connected Layer(FC) 연산을 수행합니다.
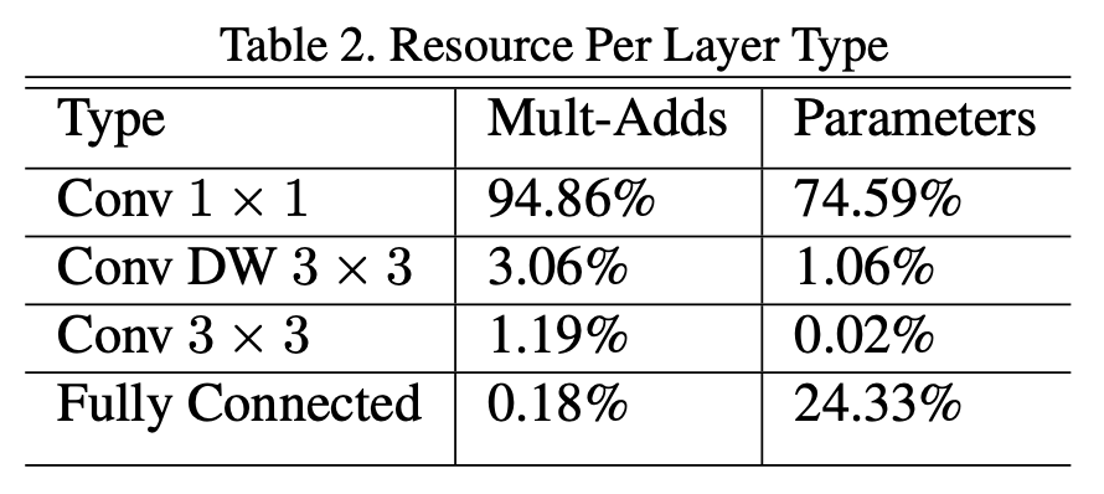
위 표는 MobileNet의 전체 연산량에서 해당 연산량이 차지하는 정도를 보여줍니다.
- 위 표에서 DW는 depthwise Convolution를 의미합니다. 3프로 밖에 차지하지 않았습니다.
- MobileNet 구조 맨 처음에 수행하는 convolution 3x3은 1프로 정도이고,
- 마지막 Fully Connected Layer는 0.18프로 밖에 차지 안 하는데,
- 중간중간 계속 발생하는 1x1 pointwise Convolution이 전체 연산의 95프로를 차지합니다.
나머지 부분에서는 좋은 연산량을 보여주었지만, "Conv 1x1"에서 Feature map을 1x1 연산을 전부 수행해주기 때문에 어쩔 수 없이 이렇게 큰 연산량을 가집니다.
이러한 1x1 pointwise Convolution에서의 큰 연산량의 해결방안으로 나온 것이 GhostNet입니다.
Method

현재 보이는 사진은 ResNet에서 첫번째 생성된 feature map을 시각화한 것입니다.
현재 화살표로 연결되어 있는 것처럼, 보이는 30개의 feature map 사이에서도 특히 더 유사한 feature map들을 볼 수 있습니다.
여기서 서로 유사한 두 사진을 보면 스패너 그림으로 화살표로 연결되어 있는데, 하나의 feature로 유사한 다른 하나의 feature을 도출할 수 있다는 뜻입니다.
여기서 원래의 feature을 intrinsic feature, 그리고 intrinsic feature을 통해 뽑아낸 feature을 ghost feature라고 합니다.
이 ghost를 통해 중복되는 Convolution을 줄이기 때문에, 이름이 GhostNet입니다.
1x1 Convolution에서의 연산량이 불가피하다면, 이렇게 애초부터 Convolution 해야하는 feature map의 개수를 처음부터 줄여버리겠다는 아이디어입니다.
Ghost Module

GhostNet은 MobileNet에서 발전한 것이기 때문에, 여기서도 마찬가지로 맨 처음에 기본 Convolution 연산으로 시작합니다.
그리고 이렇게 기본 Convolution 연산을 통해 처음으로 나온 feature가 intrinsic feature입니다.
- 이 Intrinsic feature가 여기 노란색 처럼 있으면,
- 이제 linear한 cheap operation으로 Ghost feature을 만들고,
- 마지막에 원래의 intrinsic feature을 identity mapping 해주는 것입니다.
Cheap Linear Operation
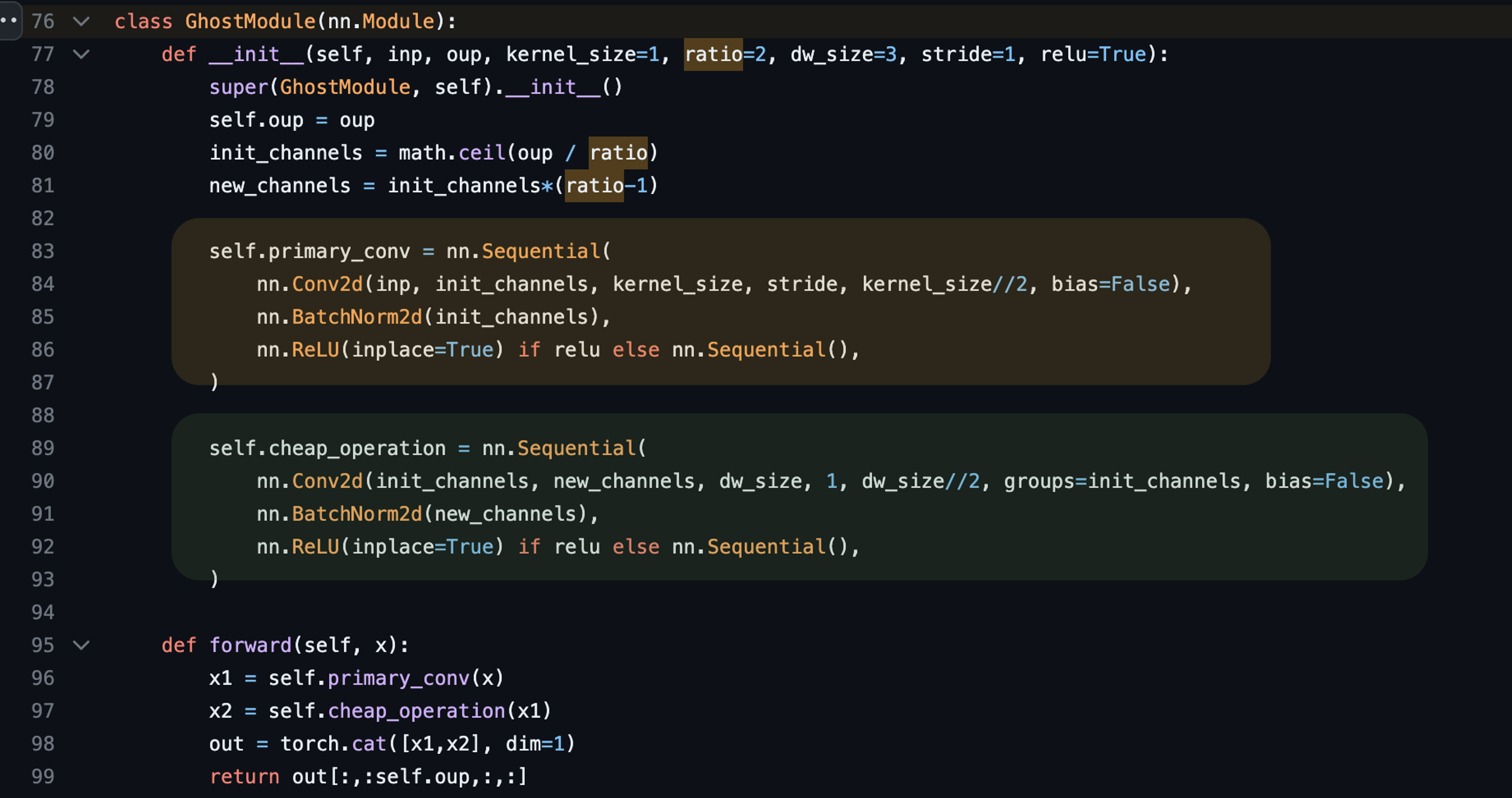
여기서 "cheap linear operation", 즉 "저렴한 선형 작업"으로 ghost feature을 만든다고 했는데 논문에서는 별 다른 공식이 없이 말로 쭉 풀어써놔서, 그냥 코드를 가져왔습니다.
위에 노란색 박스가 일반 primary convolution이고, 아래 초록색 박스가 지금 말씀드리는 저렴한 Linear 작업이라는 것입니다.
근데 코드를 보시면 아시겠지만 그냥 depthwise convolution 작업과 동일합니다.

정리하면, Ghost 모듈은
- 맨 처음 input을 일반 Convolution 연산하여 intrinsic feature을 뽑고,
- 이 intrinsic feature을 각각 depthwise convolution하여 구한 ghost feature를
- 원래 intrinsic feature와 더해서 사용한다는 개념입니다.
위 그림에 잘 정리되어 있습니다.
Visualization of Feature Maps

그리고 이 depthwise convolution은 아까 MobileNet에서 말씀드렸듯이, 기존 Convolution보다 연산량이 훨씬 적었습니다.
- 그런데도 불구하고 이 사진을 보시면, 왼쪽은 이 Cheap operation으로 구한 Feature map이고,
- 오른쪽은 일반 Convolution으로 구한 feature map입니다.
사진 보시면 ghost로 구한 feature map들이 충분히 일반 Convolution으로 구한 feature map의 역할을 수행할 수 있는 것을 보실 수 있습니다.
거기에다가 연산량은 대폭 줄었습니다.
Ghost BottleNeck

이 ghost module을 사용해 stride에 따라서 이렇게 bottleneck 구조를 사용합니다.
GhostNet Architecture
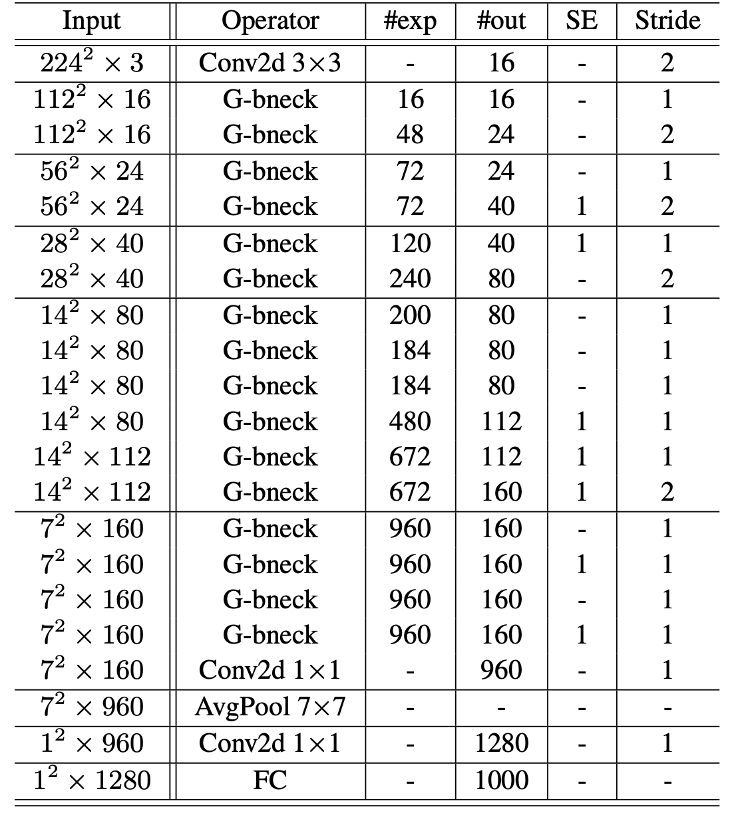
전체적인 GhostNet의 구조는 이렇습니다.
- 맨 처음에 일반 3x3 Convolution 연산을 해주고,
- ghost bottleneck 구조를 반복합니다.
이 전반적인 구조는 이전 글에서 말씀드린 MobileNet과 거의 유사합니다.
가운데 Operator는 Ghost Module로 변경되었습니다.
Experiments

왼쪽 표를 보시면 GhostNet은 다른 모델보다 FLOPs는 낮은데, Accuracy는 제일 높은 것을 볼 수 있습니다.
그리고 오른쪽 그래프에서는 GhostNet이 경량화 모델 중에서 기존의 SOTA 였던 MobileNetV3도 뛰어넘은 것을 볼 수 있습니다.



