*본 내용은 논문의 상세한 분석이 아닌, 간단한 복기용 정리입니다.
이 논문은 Image Classification을 타겟으로 한 2019년에 발표된 논문입니다. 먼저 결과부터 보여드리겠습니다.

이전에 다뤘었던 ResNet, DenseNet, SENet 등의 모델이 보이는데요. 이러한 ImageNet 데이터셋 정확도에 초점 맞춘 모델들의 성능을 EfficientNet이 크게 상회를 했습니다. 이러한 성능을 어떻게 내게 되었는지 설명하겠습니다.

EfficientNet은 새로운 모델을 찾아서 성능을 올리는 것이 아니라, 기존 모델을 바탕으로 Complexity를 높여 정확도를 올리는 방식의 모델입니다.
지금 보시는 그림은 이미 존재하는 모델의 복잡도를 키워 성능을 올려주는 여러 방법인데요. 대표적으로 filter의 개수를(channel의 개수를) 늘리는 width(너비) scaling과, layer의 개수를 늘리는 depth scaling, 그리고 input image의 해상도를 높이는 resolution scaling 이 자주 사용됩니다.
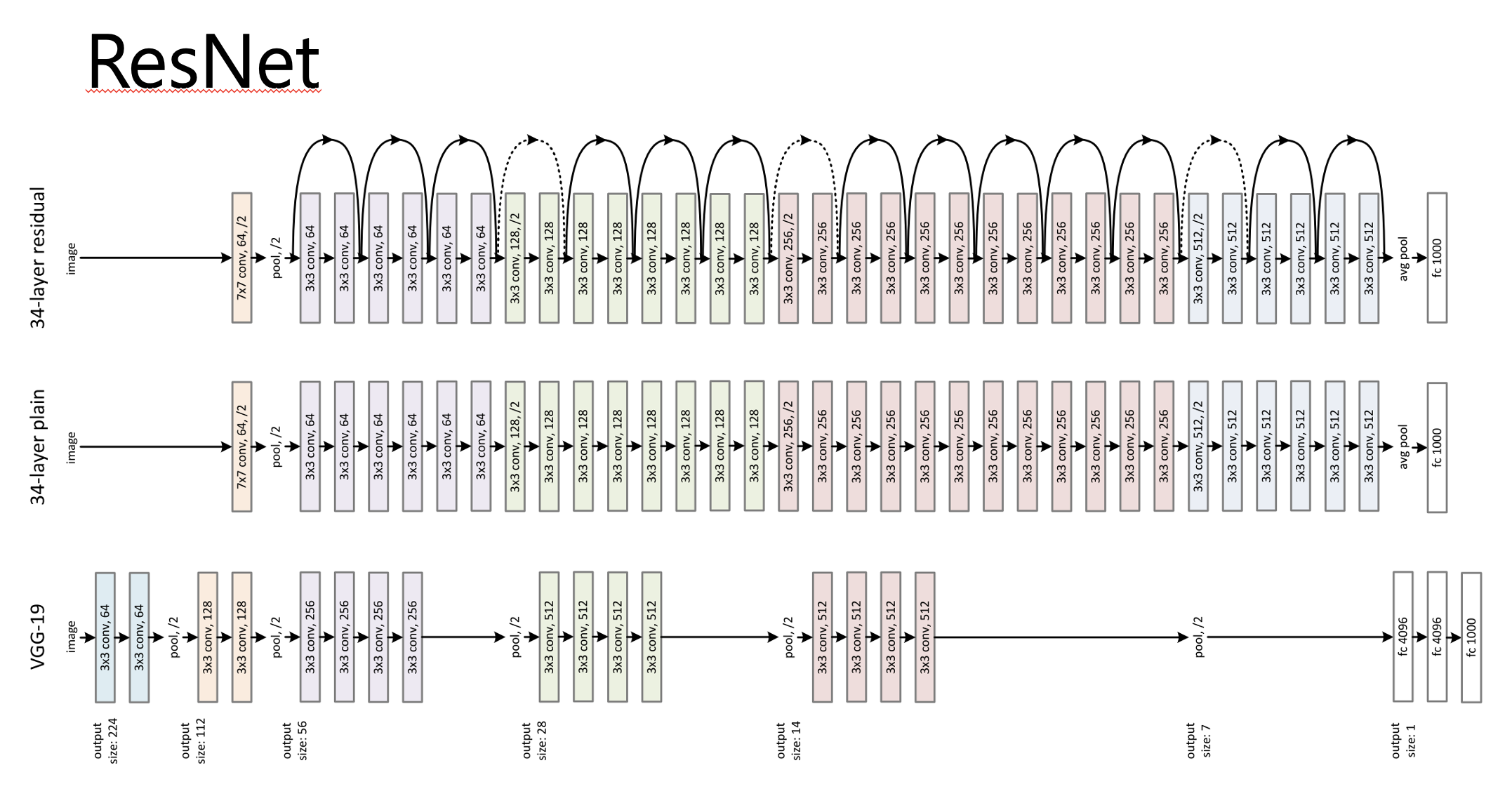
ResNet이 depth scaling을 통해 모델의 크기를 조절하는 대표적인 모델이죠. 여기 그림에서 맨 위에 모델이 ResNet인데, 일반 컨볼루션 모델에서 깊이 많이 깊어진 것을 볼 수 있습니다.
ResNet에 대한 게시물은 아래에 첨부했습니다.
https://stevenkim1217.tistory.com/entry/ResNet-%EA%B0%9C%EB%85%90-%EC%A0%95%EB%A6%AC
[논문정리] ResNet 개념 정리
*본 내용은 논문의 상세한 분석이 아닌, 간단한 복기용 정리입니다. Residual Learning ResNet의 핵심인 Residual Learning입니다. 기존 방식은 input으로 x를 받아서 두개의 weight layer을 거치고, 학습을 통해
stevenkim1217.tistory.com
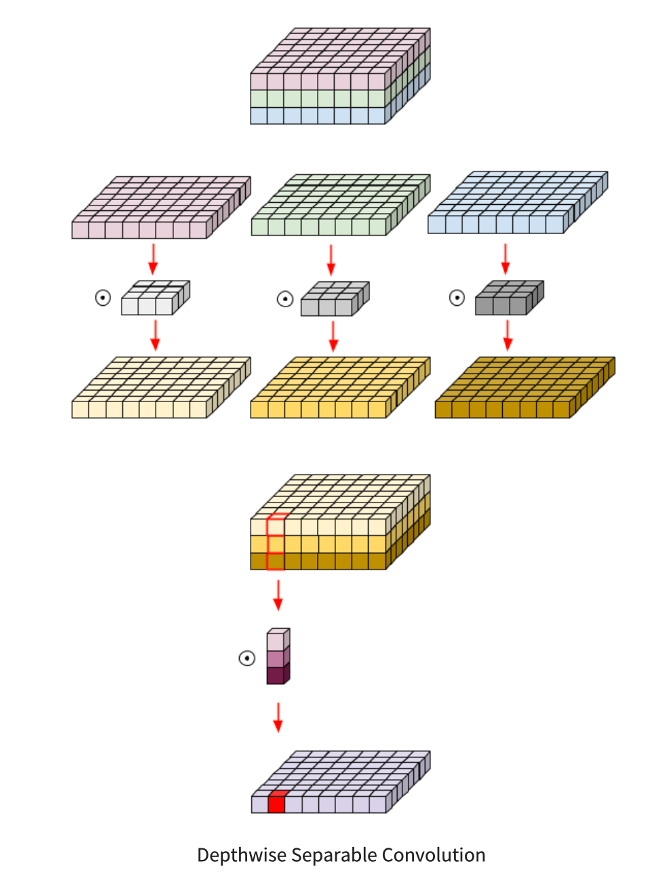
그리고, 이전에 발표했던 내용 중에 MobileNet, ShuffleNet 등이 너비 scaling을 통해 모델의 크기를 조절하는 대표적인 모델입니다.
MobileNet에 대한 게시물은 아래에 첨부했습니다.
[논문정리] MobileNets: Convolutional Neural Networks for Mobile Vision Applications
*본 내용은 논문의 상세한 분석이 아닌, 간단한 복기용 정리입니다. Introduction MobileNet의 핵심 아이디어는 Depthwise Separable Convolution입니다. 이 개념은 Depthwise Convolution과 Pointwise Convolution을 조합하
stevenkim1217.tistory.com
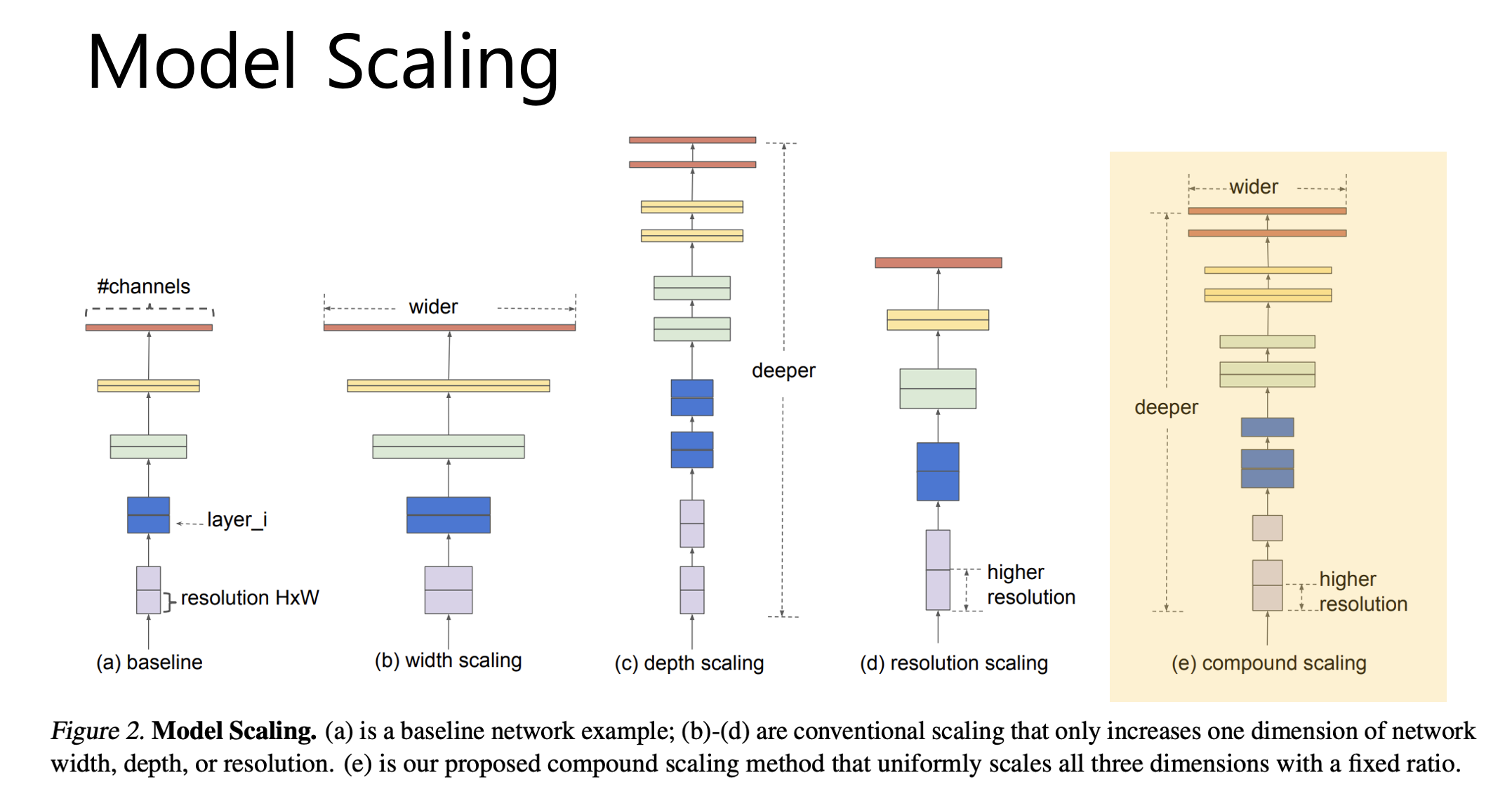
하지만 이 EfficientNet 이전의 방식들에서는 각각 한가지씩만 사용했지 위의 3가지 scaling을 동시에 고려하는 경우가 거의 없었습니다.
EfficientNet에서는 이 여러 Scale을 동시에 조절해서 성능을 올립니다. 이 과정에서, 결국 여러 파라미터를 조정하여 최적의 결과를 찾는 것이므로, 이 조정과정을 살펴보겠습니다.
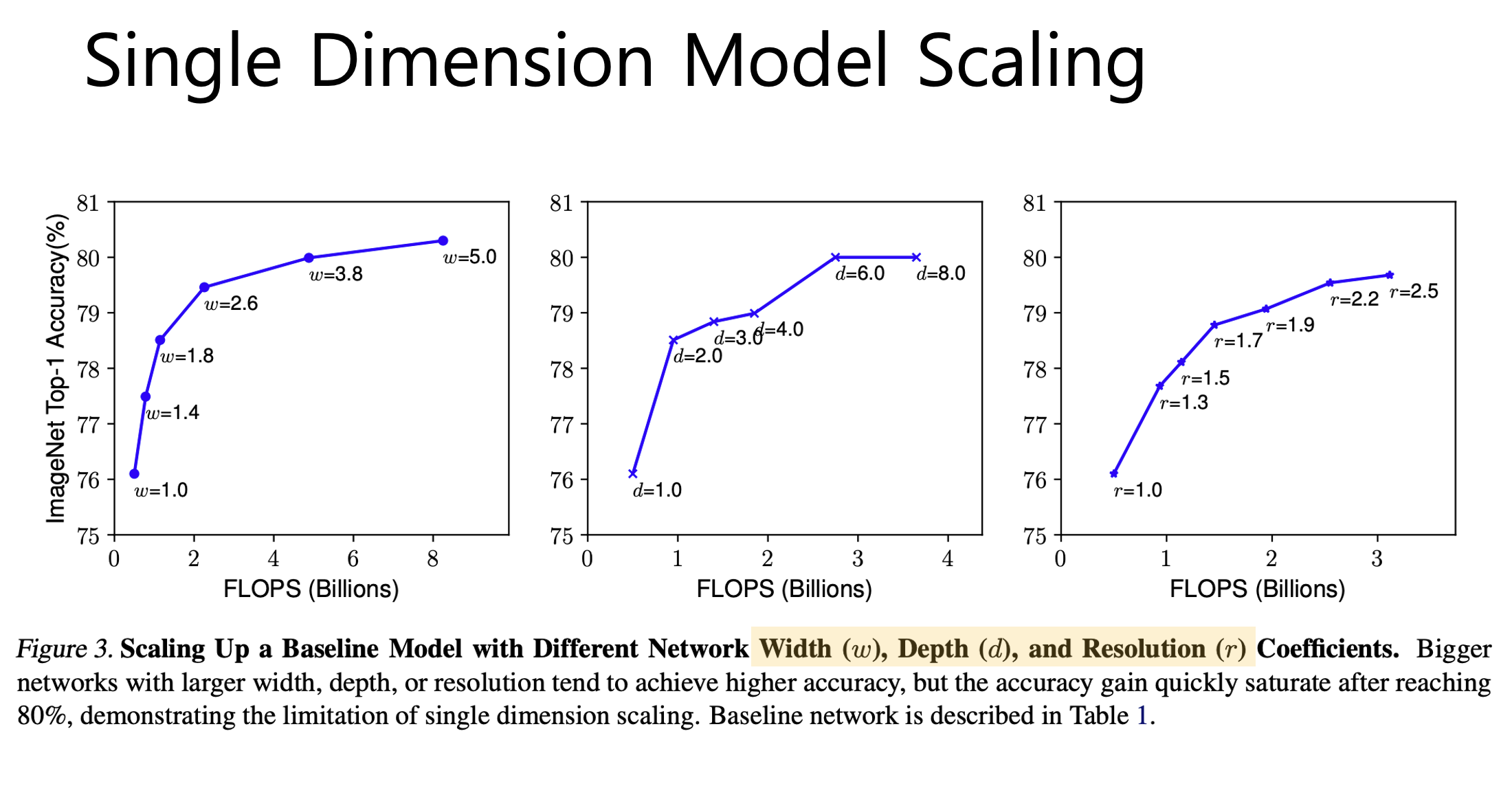
실제로 3가지 scaling 기법에 대해 각 scaling 기법마다 나머지는 고정해두고 1개의 scaling factor만 키워가며 정확도의 변화를 측정하였습니다.
그림을 보시면 width scaling, depth scaling 은 비교적 이른 시점에 정확도가 포화되어서 더이상 오르지 않고, 그나마 마지막 resolution scaling이 키우면 키울수록 정확도가 점진적으로 잘 오른다는 것을 이 한가지 factor을 조정하는 과정에서 확인했습니다.
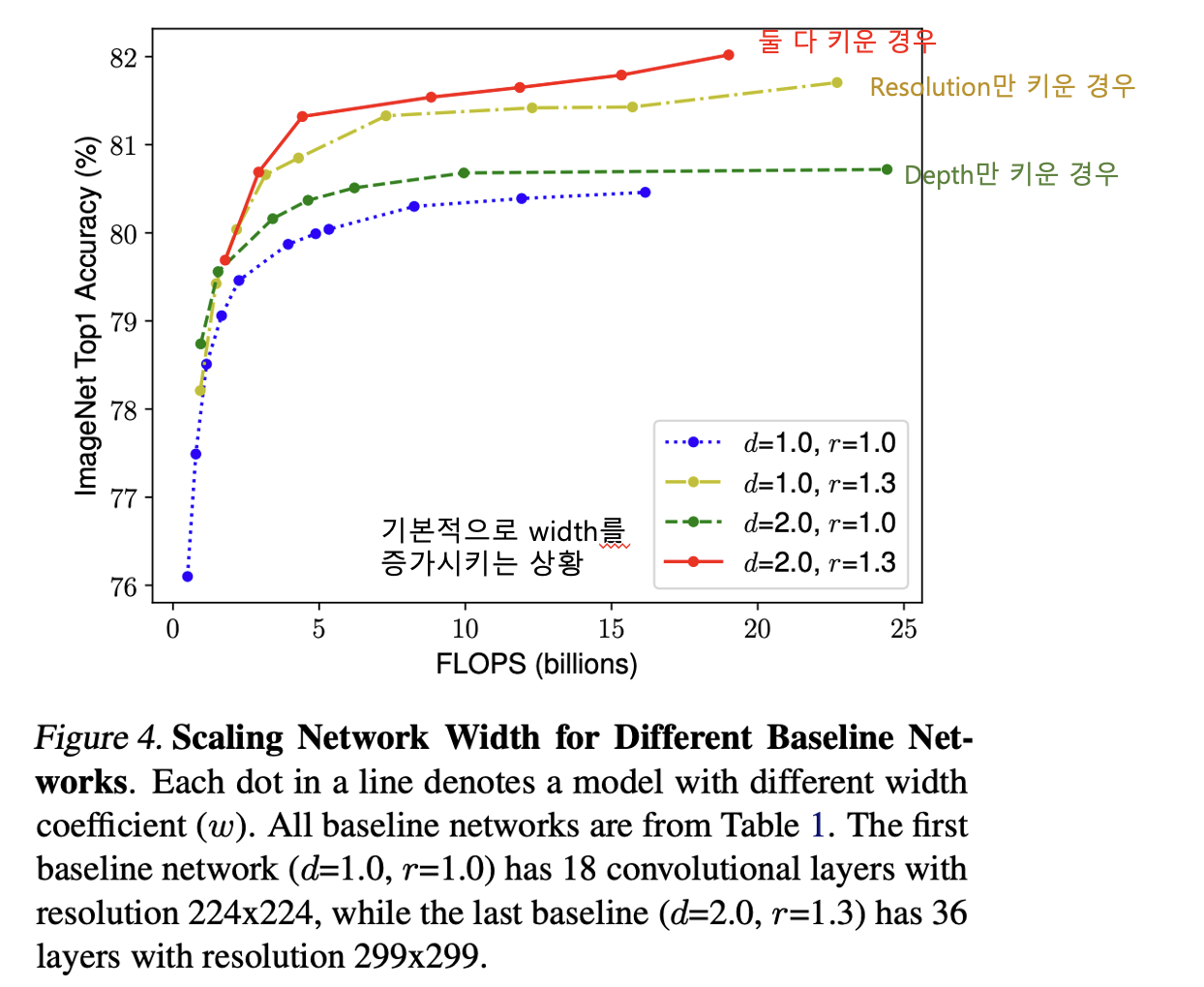
이번에는 아까 첫번째 그래프에서 depth(d)와 resolution(r)을 고정해두고 width만 조절하는 상황에서, depth와 resolution도 조절하며 변화를 측정하는 실험을 수행하였습니다.
여기 그래프를 보시면, 맨 처음 파란색 그래프에서 depth(d)만 키운 것이 초록색 선이고, resolution(r)만 키운 것이 노란색 선인데요. 이 둘만 비교했을 땐, depth를 키우는 것 보다는 resolution을 키우는 것이 정확도가 좋음을 알 수 있고, 이번엔 빨간색 선을 보면, 한두가지 scaling factor만 키워주는 것 보다 3가지 scaling factor를 동시에 키워주는 것이 가장 성능이 좋음을 실험적으로 보여주고 있습니다.
앞의 실험들을 통해서 3가지 scaling factor를 동시에 고려하는 것이 좋다는 것을 알았는데, 그럼 어떻게 최적의 비율을 찾아서 실제 모델에 적용했는지 보겠습니다.
우선 이 논문에서는 모델(F)를 고정하고 depth(d), width(w), resolution(r) 3가지를 조절하는 방법을 제안하고 있는데, 이때 고정하는 모델(F)를 좋은 모델로 선정하는 것이 사실 제일 중요합니다. 아무리 나머지 scaling factor를 조절해도, 초기 모델 자체의 성능이 낮다면 임계 성능도 낮기 때문입니다.
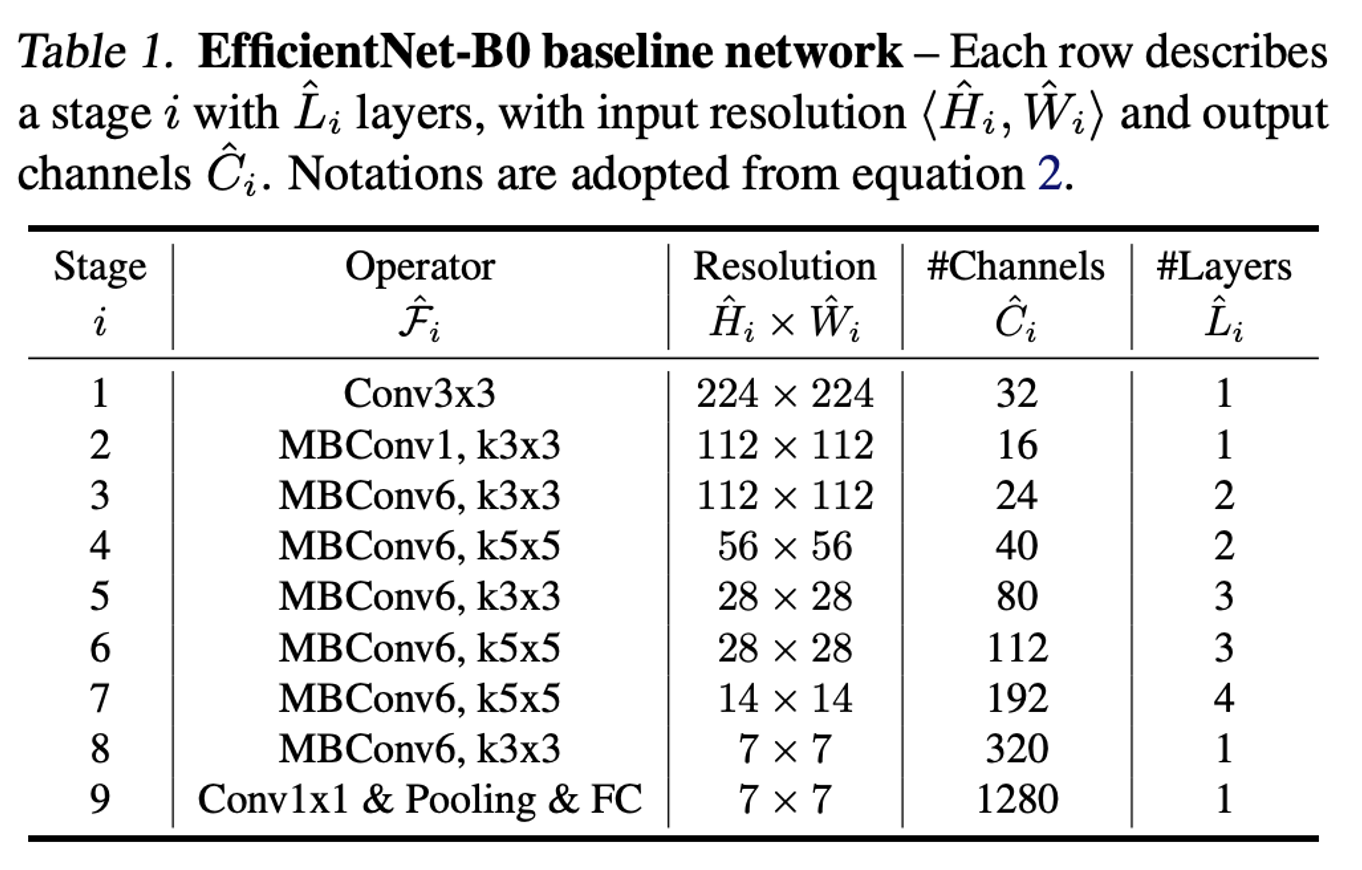
여기에서는 AutoML 모델인 MnasNet으로 모델을 탐색하였고, 이것으로 찾은 작은 모델을 EfficientNet-B0 이라 부르고 있습니다. 화면에 보이는 아키텍처를 가지고 있고요,
말씀드렸다시피 모델 구조는 MnasNet과 거의 유사하며 위의 표와 같은 구조로 구성이 되어있습니다. 이제 이 모델을 기점으로 3가지 scaling factor를 동시에 고려하는 Compound Scaling 을 적용하여 실험을 수행합니다.

우선 depth, width, resolution 은 각각 알파, 베타, 감마로 나타내며 각각의 비율은 노란색 박스 조건을 만족시켜야 합니다. 이 때 width와 resolution에 제곱이 들어가고 depth는 그냥 곱해졌는데요. 이유는, depth는 2배 키워주면 FLOPS도 비례해서 2배 증가하지만, width는 출력 layer에서 한 번, 다음 입력 layer에서 한 번 총 두번 연산이 되기 때문에 제곱해줍니다. resolution은 이미지의 가로x세로를 의미하기 때문에 제곱 배 증가합니다.
그래서 이젠 알파, 베타, 감마 값을 결정하는데, grid search를 이용해서 결정합니다. 본 논문에서는 이렇게 결정한 값이: 알파 값은 1.2, 베타 값은 1.1, 감마 값은 1.15를 사용했습니다.
그 뒤 전체 모델의 사이즈는 알파, 베타, 감마에 똑같은 파이만큼 제곱하여 조절을 하게 됩니다. 방금 구한 3개의 scaling factor는 고정한 뒤에, 파이를 1부터 시작해서 키워주며 모델의 사이즈를 키워주고 있습니다. 파이 값이 변함에 따라서 B0부터 B7모델까지 만듭니다.
그래서 아까 처음에 설명했듯이, scaling factor는 세가지를 동시에 조정했을 때 가장 성능이 좋습니다.
이 세가지 factor을 “파이”로 동시에 조정을 하게 되면서 점점 모델 복잡도를 올려, 성능을 올리는 전략입니다.
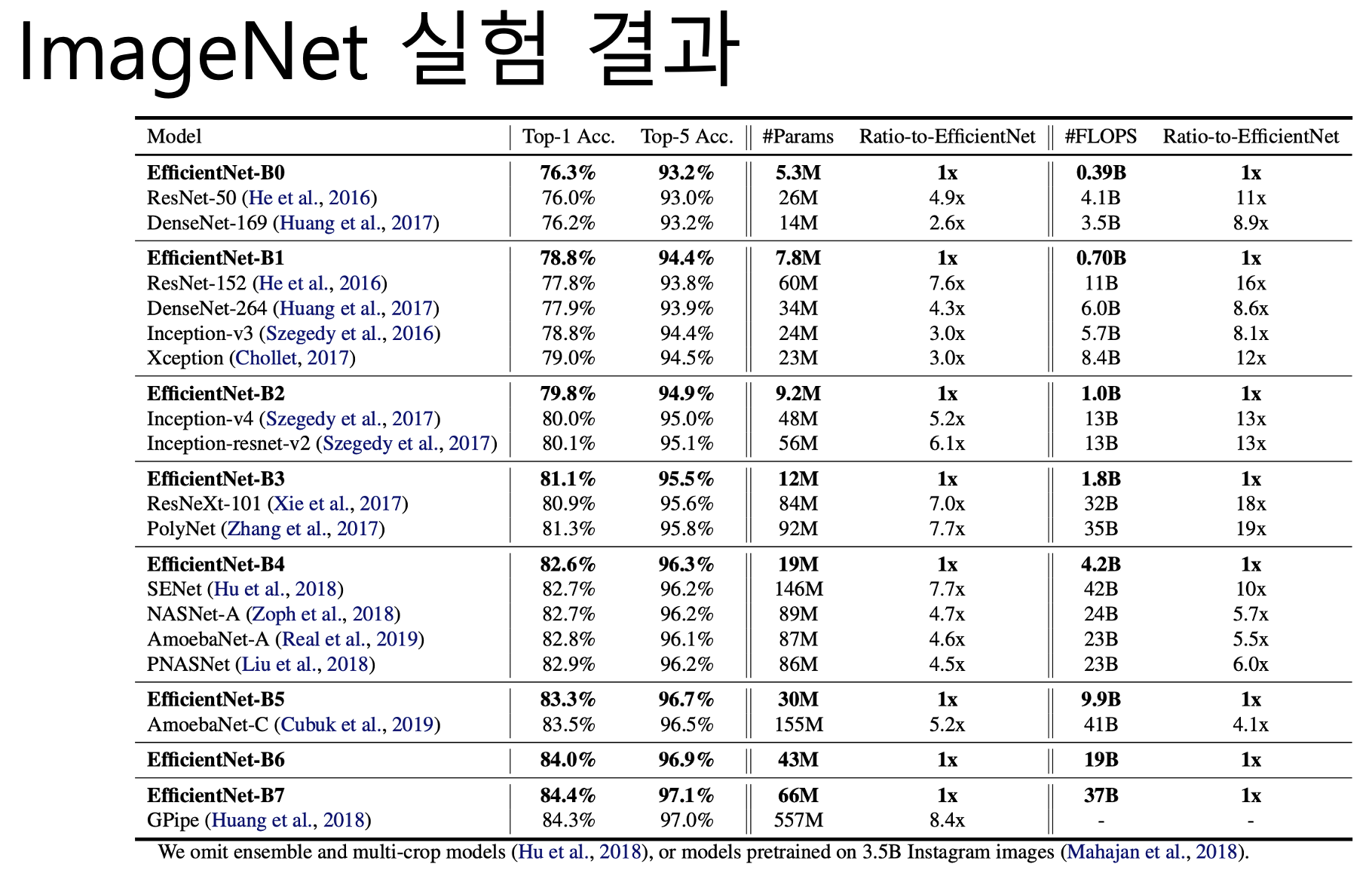
이 B시리즈 모델과 기존의 모델을 비교한 표입니다. 파이값을 증가시켜 모델을 복잡하게 할 수록성능이 점점 좋아지는데요. 기존의 모델들을 하나씩 제쳐오다가, B7 모델에서는 기존 SOTA인 GPipe의 성능을 이겼습니다.
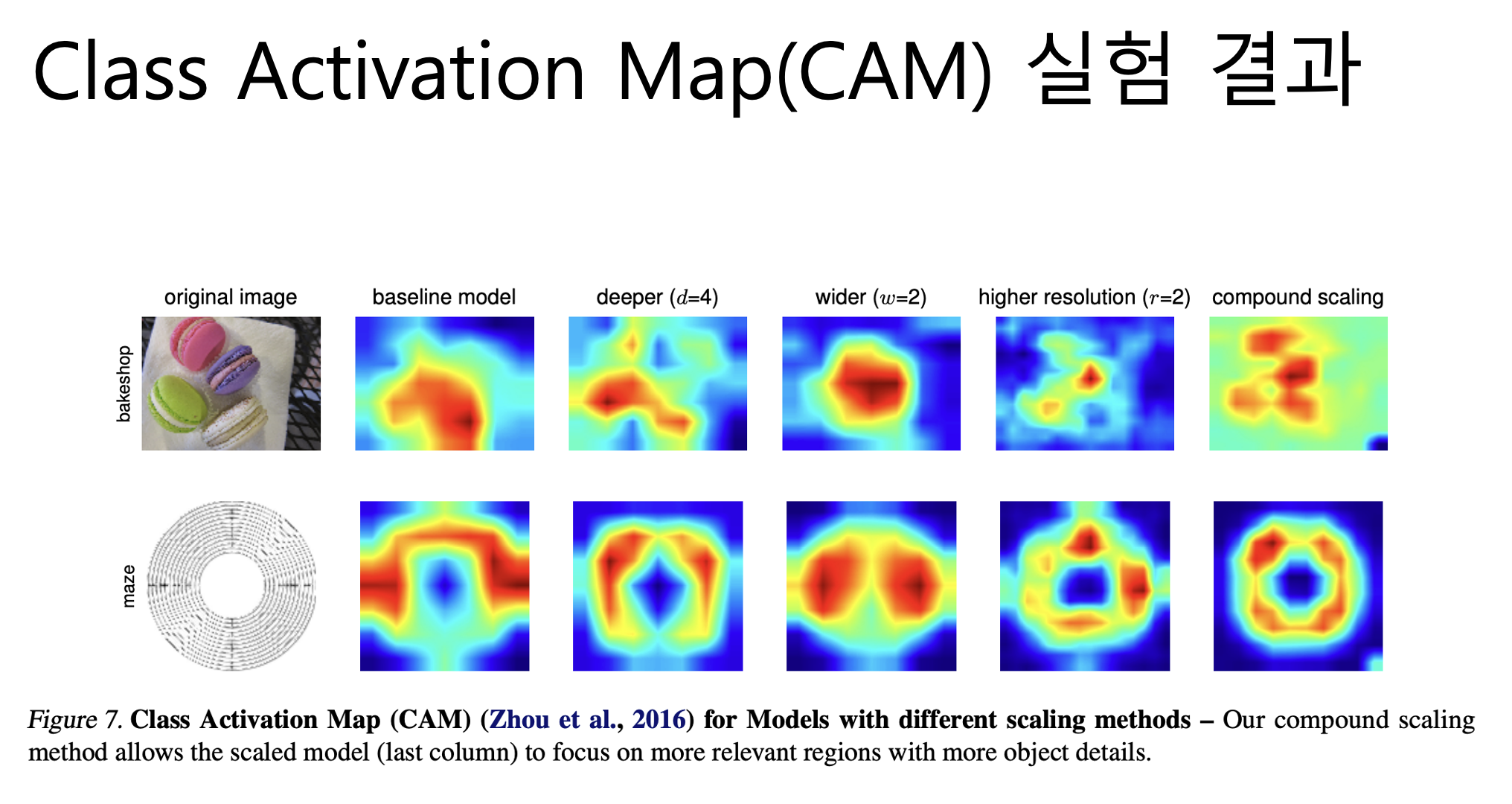
마지막으로 모델이 이미지를 분류할 때 이미지의 어느 영역에 집중했는지 확인할 수 있는 Class Activation Map(CAM)을 뽑아보았는데, 3개의 scaling factor를 각각 고려할 때보다 동시에 고려하였을 때, (보시면 이 마지막 사진들이) 더 정교한 CAM을 얻을 수 있다는 점도 인상깊은 결과입니다. 그래서 결론은 기존에는 scale을 하나씩만 조정하며 성능 향상을 기대했는데, EfficientNet은 scale을 여러개를 동시에 조정해서 성능을 대폭 향상했음을 보여줍니다.



