*본 내용은 논문의 상세한 분석이 아닌, 간단한 복기용 정리입니다.
Abstract
- Transformer 구조가 NLP에서 사실상 표준이 된 반면, Computer Vision(이후 CV) 분야에서는 제한적이었다.
- CV에서 Attention은 CNN과 결합되거나, CNN의 특정 요소를 대체하는 용도로만 사용되었다.
- 발표팀은 Attention의 CNN에 대한 이러한 의존이 필수적이지 않다는 것과, image를 patch로 잘라 Sequence 형태로 사용하여 transformer에 직접적으로 사용함으로써 Classification 작업을 잘 수행할 수 있음을 보였다.
- 거대한 데이터셋으로 pre-train하고, 중간-작은 사이즈의 데이터셋에 대해 transfer 하는 방식으로 기존의 CNN기반 SOTA를 능가하는 성능과 적은 계산량을 보였다.
1. Introduction

Self-attention-based 구조인 Transformer은, NLP에서 거의 표준으로 사용되고 있다. 이는 거대한 text 코퍼스로부터 pre-train한 후, 작은 데이터셋에 대해서 fine-tune하는 방식으로 이루어진다. 이 Transformer의 계산 효율성과 확장성 덕분에, 거대한 (100B가 넘는 파라미터를 가진) 모델도 학습할 수 있게 되었다. 모델과 데이터셋이 진화함에도, 이 Transformer은 좋은 성능을 보여주고 있다.
반면, CV 분야에서는 여전히 CNN 기반 모델들이 지배적이었다. 위와 같은 NLP의 성공에 영감을 받아 CNN과 self-attention을 결합하려는 여러 시도가 있었다. 심지어 CNN 구조를 통채로 Transformer 형태로 바꾸려는 시도도 있었다. 이러한 후속 모델들은 이론상 효율적으로 보이나, specialized attention 패턴을 보이는 등 효율적이지 않았다.
발표팀은 이 논문에서 NLP의 Transformer를 가능한 수정을 거치지 않은 채로, 이미지에 직접 적용하는 방식의 실험을 수행했다.
"NLP에서 Transformer에 단어 배열을 input으로 사용하듯, 이미지를 patch로 나누고 이 나누어진 patch에 선형적인 Sequence를 부여하여 이 이미지 patch의 배열을 Transformer의 input으로 사용하자."는 Transformer의 핵심 아이디어를 바탕으로 ImageNet과 같은 중간 사이즈의 데이터셋으로 모델을 학습시켰는데 좋지 않은 성능을 보였다.
이는 충분히 예견된 결과였는데, Transformer에는 CNN의 "inductive bias(유도 편향)"이 부족하여, 충분하지 못한 양의 데이터로 학습할 때 일반화가 잘 되지 않는다는 특성 때문이었다.
1.2. Inductive Bias
우선, Inductive bias는 "머신러닝 문제의 해결을 위해 의도적으로 사용하는 assumption(가정)"이다. 이 가정은 사전 정보를 통해 도출한다.
그렇다면, Inductive bias가 부족하다는 것은 무슨 의미인가? DeepMind와 Google Brain이 발표한 "Relational inductive biases, deep learning, and graph networks"논문에서 이에 대해 설명한다.

우리는 일반적으로 특정 데이터셋에서 더 좋은 성능을 얻기 위해, 우리가 미리 알고 있는 사전 정보를 바탕으로 머신 러닝 모델에 강제적으로 Relational inductive bias를 설정한다. 위 예시에서 볼 수 있듯, 특정 Component를 이용하는 경우 해당하는 inductive bias를 사용한다.

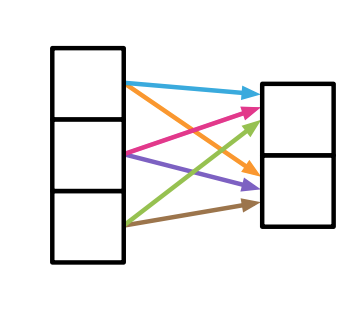
Fully connected layer의 경우, 모든 weight가 독립이고 가중치 간의 공유가 존재하지 않는다는 특성에 의해, Inductive bias가 약하다. 현재 화살표의 색은, 동일한 가중치가 공유되는 경우를 보여준다.

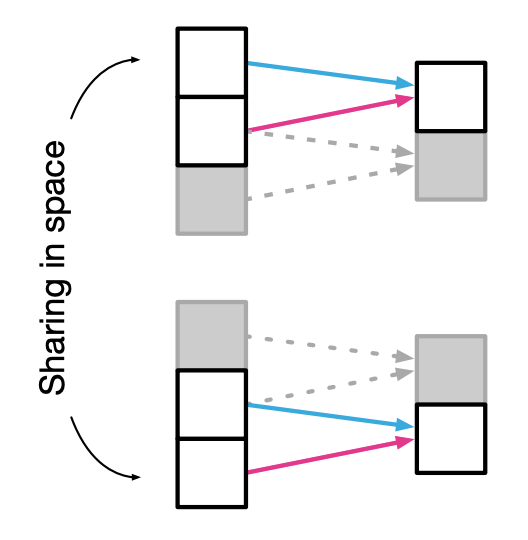
Convolutional layer의 경우, local 필터를 input 데이터에 반복적으로 적용하므로, 가중치 간의 공유가 발생한다. 발생하는 공유는 위 사진에서 같은 색의 화살표로 표시된다. 따라서 Convolution layer는 filter에 의해 다음 layer로 위치 정보, 즉 locality를 전달한다.


Recurrent layer의 경우, 같은 function이 시간을 매개로 다른 진행 과정에 반복적으로 적용된다. 이 또한 공유가 발생함을 알 수 있다. Recurrent layer은 Inductive bias로 가지는 Sequentiality를 다음 layer로 전달한다.
2.1. Method

NLP에서 가장 대표적인 구조 "Self-Attention”을 활용한 Transformer를 Vision task에 차용한 것이다. Transformer의 고유한 특징에 의해 계산 효율성(Efficiency)이나 확장성(Scalability)이 좋고, 사전 학습 비용이 상대적으로 저렴하고, 데이터셋이 크면 클수록 더 성능은 높아진다는 특징을 가지고 있다.
이제 비전 트랜스포머의 네트워크 구조에 대한 설명은 다음과 같습니다.
우선 인풋 이미지를 9개의 패치로 나누어 준다. 이후 순서대로 각각의 패치를 임베딩해서 트랜스포머 인코더에 넣어준다.
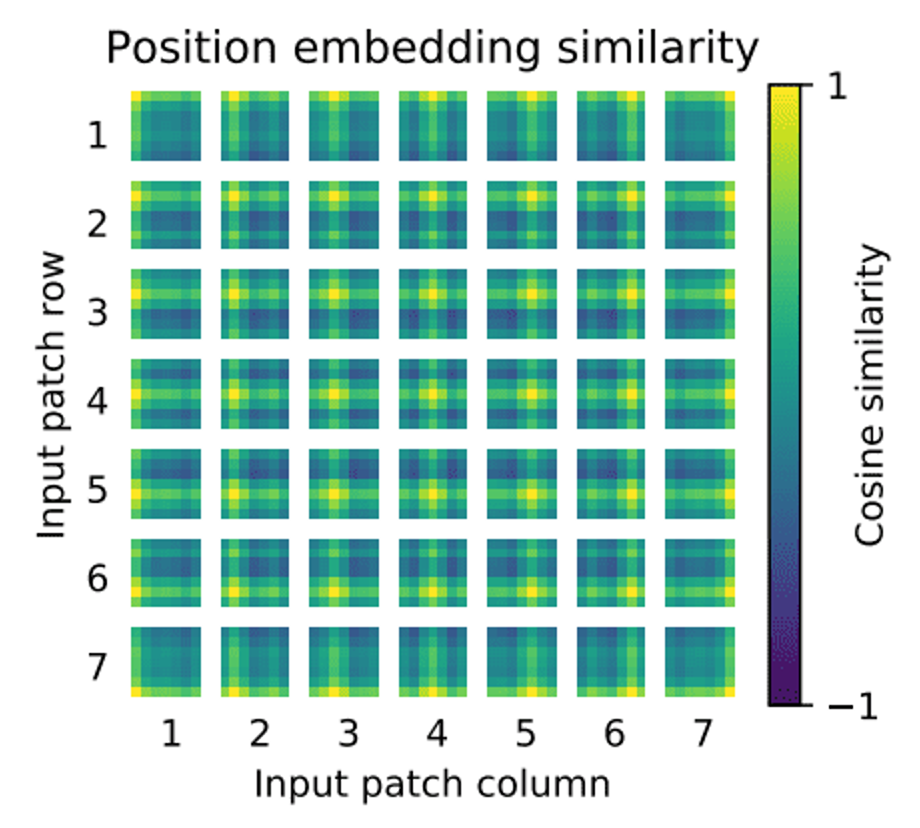
이때 순서가 중요하므로 각 Position Embedding을 더해주어 위치값을 보존합니다. Position embedding은 위와 같다.
인코더에 인풋이 들어가게 되면, 각각을 모두 Normalization 시킨 후, Concatenation 한다.
이제 그 벡터를 attention 모듈에 집어넣습니다. 여기서 residual-connection 기법을 통해, Multi-head attention의 아웃풋과 통과하지 않은 원래 값을 더해 기존의 값을 보존해준다.
이후 한 번 더 Normalization 시켜준 뒤, Multi-Layer-Perceptron을 통과한 값과 기존 값을 더하는 residual-connection을 또 사용하여 최종 아웃풋을 결정합니다. 이 아웃풋을 MLP를 이용하여 어떤 이미지를 나타내는지 최종적으로 Classification 할 수 있다.

이제 Attention 모듈의 구조에 대해서 알아보자면,
self-attention 구조에 들어가기 위해서 해당 벡터에 각각의 weight vector을 곱해서 Query, Key, Value Vector을 구한다.
이제 가까운 벡터일수록 inner product를 하면 큰 값이 나오는 성질을 이용해서, Query vector를 모든 Key Vector와 dot product를 해서 Query와 가장 유사한 Key Vector을 구한다.
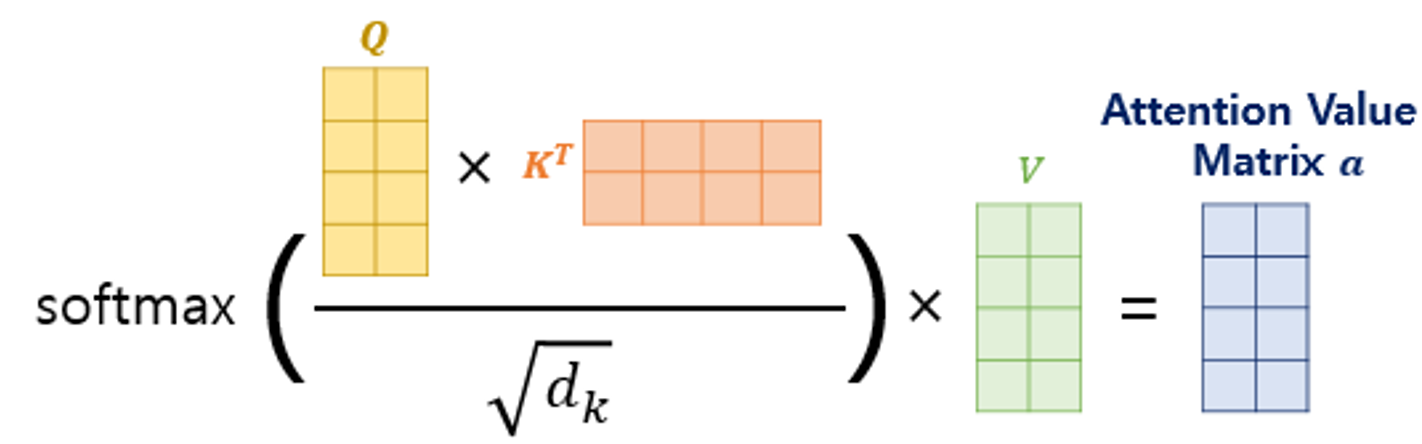
해당 dimension에 루트값으로 나눠주는 Normalization을 거치고, 이것을 softmax값에 넣고, 남은 Value vector와 모두 dot product 연산을 취해준다. 이렇게 구한 Attention score라 불리는 Attention Value matrix를 구하고, 이 모든 값들을 Summation 하여 최종적인 attention 모듈의 아웃풋 벡터를 구해준다.
2.2. Vision Transformer를 mid-size dataset으로 학습시켰을 때
Introduction에서 언급하였듯이 Transfomer는 CNN 등의 "inductive bias(유도 편향)"이 부족하여, 충분하지 못한 양의 데이터로 학습할 때 일반화가 잘 되지 않는다는 특성 때문에 ImageNet과 같은 중간 사이즈의 데이터셋으로 모델을 학습시켰는데 좋지 않은 성능을 보였다.
Vision Transformer는 Attention만을 사용할 뿐이지, CNN과 RNN 구조에 전혀 의존하지 않는다. 위에서 설명했듯이 Attention은 Query, Key, Value로 나누어서 Attention Score를 계산하고 이를 통해 Sequence가 다른 Sequence의 요소들과 어느 정도의 연관이 있는지를 나타낸다. 따라서 Fully Connected Network 처럼 모든 입력의 요소가 어떤 출력 요소던지 영향을 미칠 수 있다고 생각할 수 있다. 즉, 공유가 발생하지 않는다. 그래서, 마찬가지로 Inductive Bias가 약해진다.
이때, inductive bias와 데이터셋의 크기 사이에 연관이 있는데, 데이터셋의 크기가 작으면 작을수록 inductive bias가 주는 효율이 높다.
따라서, 본 논문에서는 Vision Transformer가 mid-sized 데이터셋에 대해서는 높은 Inductive Bias를 지닌 CNN 계열인 ResNet에 비해서 낮은 성능을 보일 수 있지만, 300M 정도의 거대한 데이터셋으로 학습을 한다면 이러한 large scale 자체가 inductive bias를 이길 수 있다고 주장한다.
이러한 비전 트랜스포머의 과정을 수식으로 정리하면 다음과 같다.

- 각각의 Linear Projection된 패치들에 Position Embedding을 더해주게 되고, 해당 값을 Normalization 시킨 뒤 Multi-Self-head-Attention(MSA)의 인풋으로 넣어준다.
- 그리고 기존의 값을 Residual connection 기법으로 그대로 더해주어 값을 보존한다.
- 이렇게 Transform 모듈을 통과하고, ouput 값을 한 번 더 Normalization 시켜주고, Multi-Layer-Perceptron(MLP)를 통과하고 residual connection 기법으로 한 번 더 기존의 값을 더해준다.
- 최종적으로 Layer Normalization을 통해서 최종 아웃풋 y벡터를 도출한다.
이렇게 Transformer Encoder를 빠져나온 y벡터를 MLP를 통해 image classification을 수행한다.
'AI 논문 리뷰(AI Paper Review) > 컴퓨터비전(Computer Vision)' 카테고리의 다른 글
| [논문정리] DenseNet 개념 정리 (0) | 2023.09.01 |
|---|---|
| [논문정리] ResNet 개념 정리 (0) | 2023.09.01 |
| [논문 정리] DeiT: Training data-efficient image transformers & distillation through attention (0) | 2023.09.01 |
| [논문 정리] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows (0) | 2023.09.01 |
| [논문정리] Convolution Neural Network (CNN) 개념 정리 (0) | 2023.09.01 |



