*본 내용은 논문의 상세한 분석이 아닌, 간단한 복기용 정리입니다.
Introduction

Swin transfomer은 텍스트와는 다른 이미지만의 특성을 고려했습니다. 이 이미지의 특성으로는, “해상도”와 “물체의 크기”가 존재합니다. 그래서 제안하는 방법은 이런 Local Window를 모델에 적용하는 것입니다.
빨간 테두리를 Window, 회색 박스 하나를 패치라고 합니다.
기존 Vision Transformer의 Window는 고정적이기 때문에 세밀한 segmentation을 하기 어려웠던 반면, Swin Transformer는
- 우선 제일 아래의 layer에서 나눠진 각 Window에 대해 각각 self-attention을 적용하고,
- 그 다음 layer에서는 window를 한 단계 병합해서 각각 self-attention을 적용하고,
- 이 과정을 반복해서 최종적으로 모든 patch가 하나의 window안에 들어와 있는 완전한 이미지에 대해서 self-attention을 적용
위와 같은 방식으로 이루어집니다.
각 layer마다 다른 해상도를 적용한 것을 알 수 있습니다.
Method
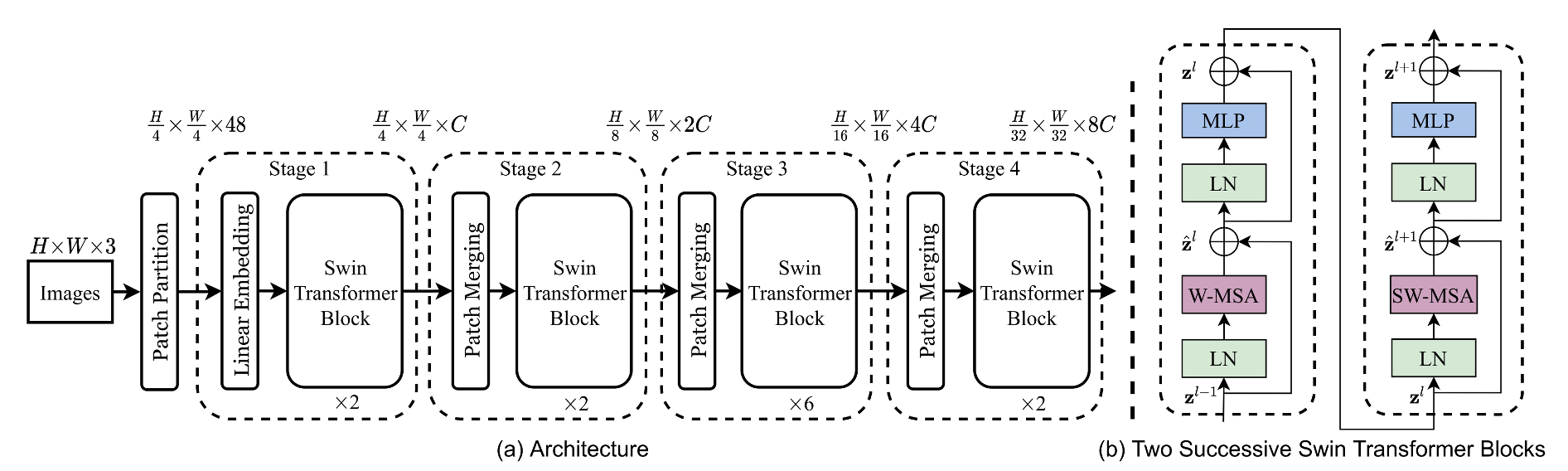
Swin Transformer의 구성입니다. Images를 일단 patch로 만들고 swin transformer block에 넣어주는 형태를 반복합니다. 방금 설명한 Patch Merging 과정이 매 stage마다 포함되어 있습니다. 이 patch merging을 통해서 해상도를 줄여줍니다.
MSA는 Multi-self-attention으로 Multi-Head-Attention과 같은 개념입니다.
1. W-MSA

빨간색 박스를 보시면, W-MSA는 패치로 구성되어있는 이미지를 윈도우로 나눠서 각 윈도우 안에서만 self-attention을 수행하는 방법을 말합니다.
2. SW-MSA
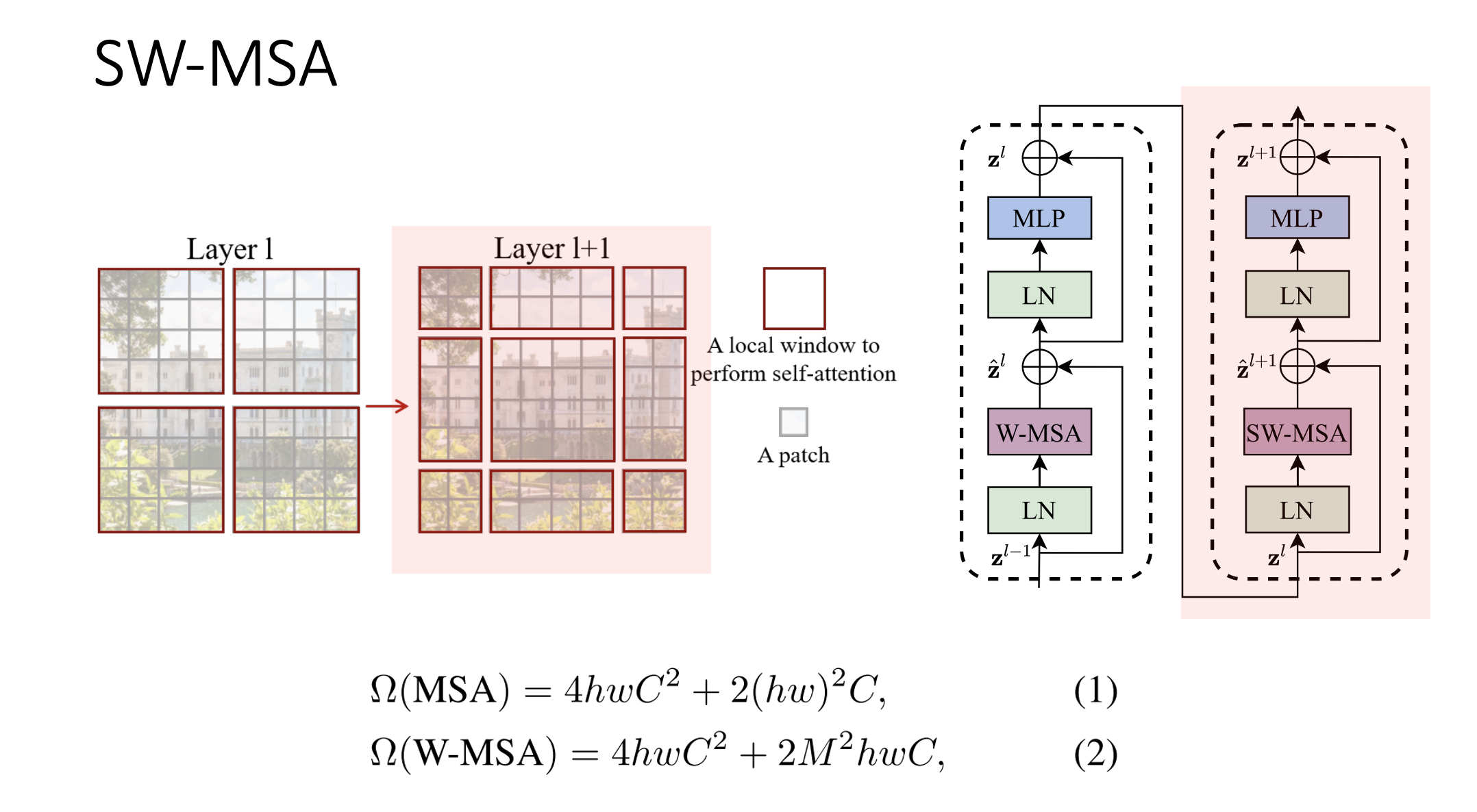
SW-MSA는 W-MSA같이 윈도우 내부가 아닌, 윈도우 “간의” self-attention을 적용해주는 과정을 말합니다.
이번의 빨간 박스를 보시면 처음에 연결되지 않았던 부분들에 대해서만 윈도우가 적용된 것을 볼 수 있습니다. W-MSA는 윈도우의 개수가 2x2였는데, SW-MSA는 윈도우의 개수가 3x3으로 늘었습니다.
이러한 비효율성을 극복하기 위해 Cyclic shift와 Attention Mask를 적용하였습니다.

다음은 MSA를 적용하기 전에 shift를 시키는 과정입니다. 그래서 cyclic shift를 이용해서 왼쪽에 있는 window를 shift size만큼 조절해서 오른쪽 아래로 이동시킵니다. 그러면 처음 layer1에서의 윈도우 개수와 같은 2x2 윈도우로 처리할 수 있게 됩니다.
하지만 이렇게 옮긴 뒤에도, 서로 다른 색은 attention이 다르게 적용되어야 합니다. 이 이유는 이미지는 인접한 pixel에서 연관성이 생기는 데, 현재 보이는 ABC는 shift를 통해 멀리서 옮겨온 patch이고, 멀리 떨어진 부분은 연관성이 존재하지 않기 때문입니다. Attention mask라는 방법을 사용해서 이 아래 사진처럼 설정한 mask 안에서만 self-attention을 적용할 수 있도록 한 것입니다.
Mask 연산이 다 끝난 후, window를 원상복귀 시킵니다.
이 SW-MSA를 통해서 window간의 연결성과 위치를 파악할 수 있기 때문에 model이 이미지를 학습할 때 도움이 됩니다.
Swin Transformer에서 한가지 더 알아야 하는 점은, 바로 Positional encoding을 처음에 적용하지 않는다는 점입니다. Swin Tansformer은 Relative Position Bias를 attention 연산 과정 중에 더해주는 형태를 취합니다.

Vision Transformer은 처음에 이미 정해진 positional embedding을 기준으로, 각 위치에 대한 positional embedding을 그냥 더해줬습니다.
이처럼 기존의 positional encoding은 absoulute coordinate에 대한 기준이였다면, Relative Position Bias는 relative coordinate에 대한 기준으로 weights을 줍니다.
이 과정에 대한 설명은 다음과 같습니다.

우선 윈도우 사이즈가 3이라고 가정하겠습니다. 먼저 x축 행렬을 구합니다. 2는 1과 같은 x축 위에 놓여있으므로 거리가 0입니다.

하지만 4는 1과 다른 x축에 놓여있고, 거리는 -1입니다. 이런 식으로 Window 안의 모든 patch에 대해 구하고, Y축 행렬도 같은 방식으로 구합니다.

그 다음 윈도우 사이즈에서 1을 뺀 값을 구한 각 x축, y축 행렬에 더합니다. 이것은 모든 값을 0부터 시작하는 Index의 형태로 만들어주기 위한 것입니다.

다음으로 X축 행렬에 윈도우 사이즈의 2배를 곱해주고 빼기 1한 값을 대입합니다. 마지막으로 이 업데이트 된 x축 행렬과 y축 행렬을 더하면 Relative Position index를 구할 수 있습니다.

이렇게 구한 B hat으로, Relative Position Bias을 만듭니다. 이 과정은 생략하겠습니다.
Experiment
Window 적용 방법에 따른 속도 비교를 설명하겠습니다.

우리가 위에서 cyclic shift를 이용하여 윈도우의 개수를 조절했는데, cyclic하지 않고 naïve하게 순차적으로 왼쪽에서 오른쪽으로, 위에서 아래로 shift하는 방법과 비교해 압도적인 속도차이를 보인 것을 확인할 수 있습니다.
Conclusion
Window를 적용함으로써 아무리 이미지의 해상도가 커져도 Window 사이즈 단위로 self-attention이 수행되기 때문에 확실히 적은 Computation Complexity가 발생할 것입니다.
또 Local window가 적용되기 때문에 Window간의 관계를 잘 학습할 수 있고, 이렇게 각 Window 간의 특성을 볼 수 있게 되니까, 한 이미지 안에서도 더 세분화된 “이미지 안의 물체의 크기” 같은 부분들을 잘 분류해낼 수 있게 된 것 같습니다.
'AI 논문 리뷰(AI Paper Review) > 컴퓨터비전(Computer Vision)' 카테고리의 다른 글
| [논문정리] DenseNet 개념 정리 (0) | 2023.09.01 |
|---|---|
| [논문정리] ResNet 개념 정리 (0) | 2023.09.01 |
| [논문 정리] DeiT: Training data-efficient image transformers & distillation through attention (0) | 2023.09.01 |
| [논문 정리] AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE (0) | 2023.09.01 |
| [논문정리] Convolution Neural Network (CNN) 개념 정리 (0) | 2023.09.01 |



