*본 내용은 논문의 상세한 분석이 아닌, 간단한 복기용 정리입니다.
Residual Learning

ResNet의 핵심인 Residual Learning입니다.
기존 방식은 input으로 x를 받아서 두개의 weight layer을 거치고, 학습을 통해 최적의 출력 H(x)를 구하는 것이 목표입니다.
근데 이제 단순히 H(x)를 출력하는 기존의 방식에서, 출력인 H(x)와 입력인 x의 차이를 학습시키는 것을 목표하는 방식으로 목적을 바꾼 것이 Residual Learning입니다.
Residual Function인 F(x) = H(x) - x를 최소화시켜야 하고 이것은 즉, 출력과 입력의 차를 줄인다는 의미가 됩니다.
여기서 x의 값은 도중에 바꾸지 못하는 입력 값이므로 F(x)가 0이 되는 것이 최적의 해이고, 결국 0 = H(x) - x로 H(x) = x가 됩니다. 즉, H(x)를 x로 mapping 하는 것이 학습의 목표가 됩니다.
이전에는 알지 못하는 최적의 값으로 H(x)를 근사 시켜야 하므로 어려움이 있었는데, 이제는 H(x) = x라는 최적의 목표값이 사전에 pre-conditioning으로 제공되기에 F(x)가 학습이 더 쉬워지는 것입니다.
ShortCut

여기 보이는 것처럼 두개의 convolutional layer를 뛰어넘는 인풋 feature map인 x를 output에 더해주는 구조를 ShortCut이라고 부릅니다.
아래의 두 shortcut의 구조를 눈에 익히고 다음 step 으로 넘어가겠습니다.



이제 이 사진을 보시면, 방금 보신 것과 똑같이 각 Convolution layer 두개를 건너뛰는 x를 더해주는 구조가 이어져 있고,
output feature map의 개수가 두배로 변할 때마다 Convolutional layer의 색이 변하는데, 이게 변할 때만 실선대신 점선이 보이는 것을 볼 수 있습니다.
실선은 기본적으로 아까 설명한 것처럼 F(x)에 인풋 x를 더한 Identity ShortCut이고, 점선으로 표시된 이 부분에서 output의 개수가 두배로 튀지만, 가로 세로 길이는 절반으로 줄어듭니다.
그래서 사이즈가 절반으로 줄어드니까, shortcut에서도 마찬가지로 feature map의 사이즈를 줄여주어야 합니다. 그래서 이때는 identity shortcut 대신 Projection shortcut을 사용하게 됩니다.
정리하면, 실선은 Identity Shortcut, 점선은 Projection Shortcut 입니다.
그리고 여기 밑에 있는 것들은, 방금 설명한 이 ResNet residual layer가 VGG-19의 3x3 Convoluion을 반복하는 기본 구조를 따랐고, 가운데는 이 VGG-19의 layer을 반복해서 많이 쌓은 모델입니다.
근데 이렇게 layer가 많아져서 deep해지면 input 정보가 손실되는데, Shortcut 개념을 추가해서 이것을 방지한 것이 ResNet 구조입니다.
ResNet Structure

이제 여기 보이시는 것처럼 layer을 얼마나 쌓느냐에 따라 ResNet 구조에 차이가 생깁니다.
ResNet 네트워크에 layer을 많이 쌓아서 연산량이랑 parameter을 늘려주어 정확도를 높였습니다.
여기 보이는 152 layer가 가장 좋은 성능을 보였고요, 여기 자세히 보시면 layer 개수가 50개 이상인 경우에는 Bottle Neck 구조를 사용했습니다.
BottleNeck
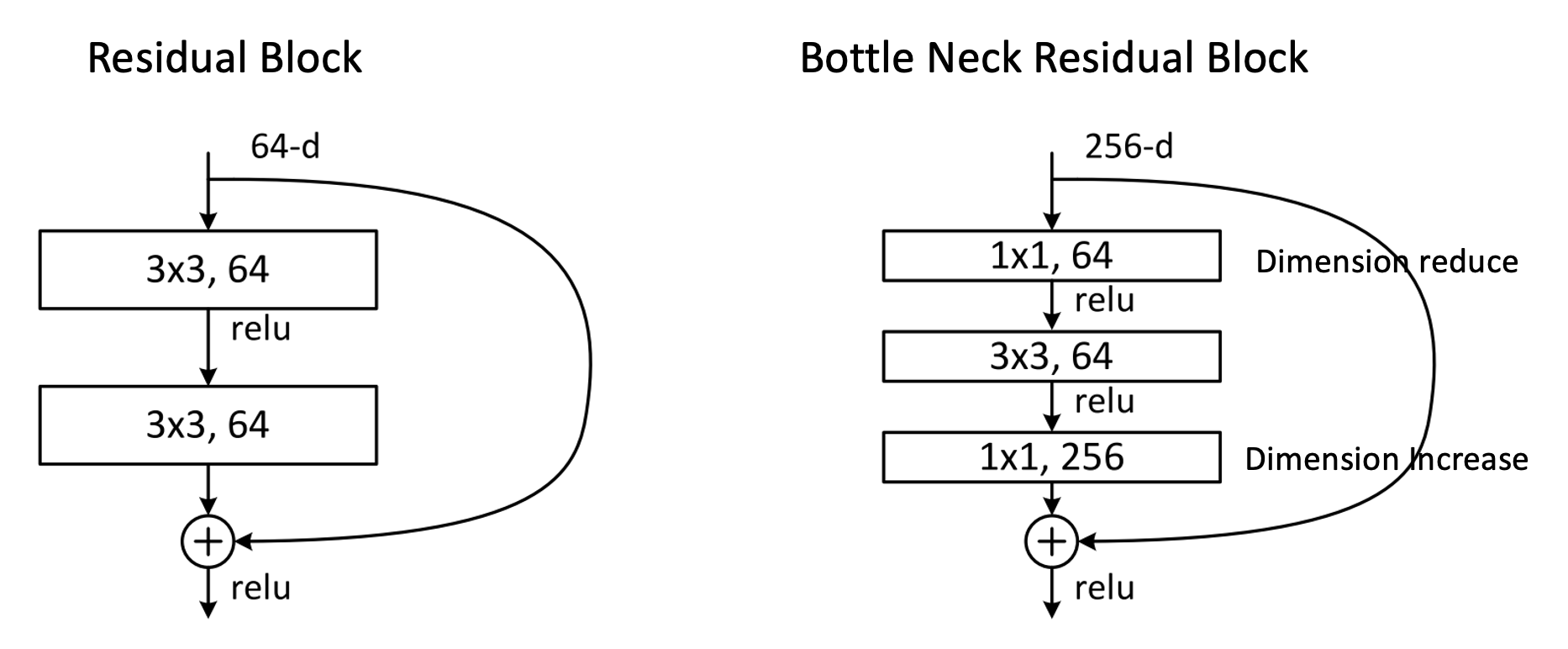
왼쪽이 일반 Residual 구조이고, 오른쪽이 Bottle Neck residual 구조인데요.
처음에 1x1 convolutional Filter을 통해 dimension을 축소시키고, 다시 마지막에 1x1 Filter을 통해 다시 dimension을 키워주는 매커니즘입니다.
맨 처음에 1x1 연산을 수행하면 feature map의 개수가 줄어들게 되고 이렇게 줄어든 feature map의 개수로 가운데 layer에서 3x3연산을 수행하면, 기존의 Residual 구조에서처럼 그냥 3x3 연산을 진행하는 것보다 연산량을 훨씬 줄일 수 있습니다.
'AI 논문 리뷰(AI Paper Review) > 컴퓨터비전(Computer Vision)' 카테고리의 다른 글
| [논문정리] CSPNet 개념 정리 (0) | 2023.09.01 |
|---|---|
| [논문정리] DenseNet 개념 정리 (0) | 2023.09.01 |
| [논문 정리] DeiT: Training data-efficient image transformers & distillation through attention (0) | 2023.09.01 |
| [논문 정리] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows (0) | 2023.09.01 |
| [논문 정리] AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE (0) | 2023.09.01 |



