*본 내용은 논문의 상세한 분석이 아닌, 간단한 복기용 정리입니다.
Introduction
이전 Vision Transformer 논문 정리 게시글에서, ViT가 ImageNet 정도의 사이즈에서는 이전 SOTA인 Convolutional layer 기반 모델인 ResNet보다 낮은 성능을 보이는 한계를 보였다고 말씀드렸습니다. (링크 참조)
[논문 정리] AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
*본 내용은 논문의 상세한 분석이 아닌, 간단한 복기용 정리입니다. Abstract Transformer 구조가 NLP에서 사실상 표준이 된 반면, Computer Vision(이후 CV) 분야에서는 제한적이었다. CV에서 Attention은 CNN과
stevenkim1217.tistory.com
그리고 거기에다가 ViT를 학습시킬 때는 데이터가 너무 크기 때문에 일반 GPU로는 절대 불가능한 어마어마한 시간이 걸리게 되는데, 이 논문에서 소개하는 DeiT는 8-GPU Single Device로 3일만에 학습을 성공했다고 합니다.
이는 비슷한 Parameter 규모를 가지는 CNN 모델을 학습시키는 데에 드는 시간과 큰 차이가 없습니다.
따라서, Transformer 모델을 비전 task에 도입한 저번 ViT 논문에 이어서, 이번 논문은 CNN Layer가 없는 Transformer 방식으로도 오로지 ImageNet 데이터셋만으로 학습을 진행했을 때 CNN과 경쟁력을 가지는 성능을 얻을 수 있다는 것을 확인했습니다.

Vision Transformer 모델에 ImageNet만 활용해서 SOTA 성능을 기록했습니다.
이는 학습과정에서 data augmentation을 추가 및 변형하고, 고해상도 이미지로 fine-tuning을 하는 방식을 통해서 이 한계를 극복할 수 있었습니다.
Transformer에 특화된 distillation technique을 제안했고, 뒤에서 자세히 설명하겠지만 distillation 토큰을 추가하는 것을 말합니다.

여기 사진을 보시면, 증류 토큰이 붙은 DeiT 모델이 ImageNet 데이터에서 기존의 ViT보다 더 좋은 성능을 낸 것을 볼 수 있습니다.

Knowledge distillation 은 NIPS 2014 에서 "Distilling the Knowledge in a Neural Network" 라는 논문에서 제시된 개념입니다. Knowledge distillation 의 목적은 "미리 잘 학습된 큰 네트워크(Teacher network) 의 지식을 실제로 사용하고자 하는 작은 네트워크(Student network) 에게 전달하는 것" 입니다.
정확히는 큰 모델의 output, 즉 Softmax값은 해당 모델이 학습한 지식을 담고 있을 것이므로, 이를 작은 모델에 전달하는 방법으로써 고안된 개념입니다.
이때 당시에 서비스에 Deploy하기 위해서 작지만 높은 성능을 보이는 모델을 만들 필요가 있어서 많이 연구되었다고 합니다.
Background: Knowledge Distillation

Knowledge distillation은 아래 보이는 크게 두가지 Loss를 최적화하는 식으로 진행이 됩니다.
이 위에 보이는 큰 Teacher 모델은 미리 사전에 학습이 완료된 상태여야 하고, 우리의 목적은 이 작은 student 모델을 학습하는 것이 목표입니다.
이 그림에서 아랫부분은 우리가 딥러닝 모델 을 학습시킬 때의 일반적인 Supervised Laerning에 해당합니다. 그래서 이 아래의 Loss function은 Cross Entropy Loss가 될 것이구요, 이 윗 부분의 Softmax를 거쳐 나온 이 두 값을 비슷하게 만들어 주는 게 핵심입니다.
여기 수식에 T는 Temperature을 의미하는데요, 이 Temperature 개념을 설명하기 위해서 Hard Label 과 Soft Label을 먼저 설명하겠습니다.
Background: Hard label vs Soft label

곰, 고양이, 개 3가지 클래스를 구분하는 모델이 있을 때, 분류 결과가 왼쪽과 같다면 Hard label, 오른쪽과 같다면 Soft label 이라고 부릅니다.

이 예시의 결과값을 보면 입력 이미지가 고양이었다고 유추할 수 있습니다.
Soft label 을 보면 입력 이미지에서 고양이와 개가 함께 가지고 있는 특징들이 어느정도 있었기 때문에 Dog class score 가 0.2 만큼 나왔다고 생각할 수 있습니다.
이때, 그래도 유사도에 따라서 차이가 있는 것이므로, 이 기여도를 Temperature hyperparameter값으로 설정합니다.

이제 이 T값만큼 나눠줘서, 이러한 Soft label 분포를 더 완만하게 해줌으로써, 정보를 더 풍부하게 주고자 하는 목적입니다.
이렇게 풍부한 정보를 가진 Teacher 모델의 지식을 Student model이 transfer 받는 과정으로 진행하게 됩니다.
Soft distillation vs Hard distillation
지금까지는 기본적인 distillation 과정에 대해서 설명했습니다.
이 논문에서 비교 분석하는 Soft distillation과 Hard distillation에 대해서 설명하겠습니다.
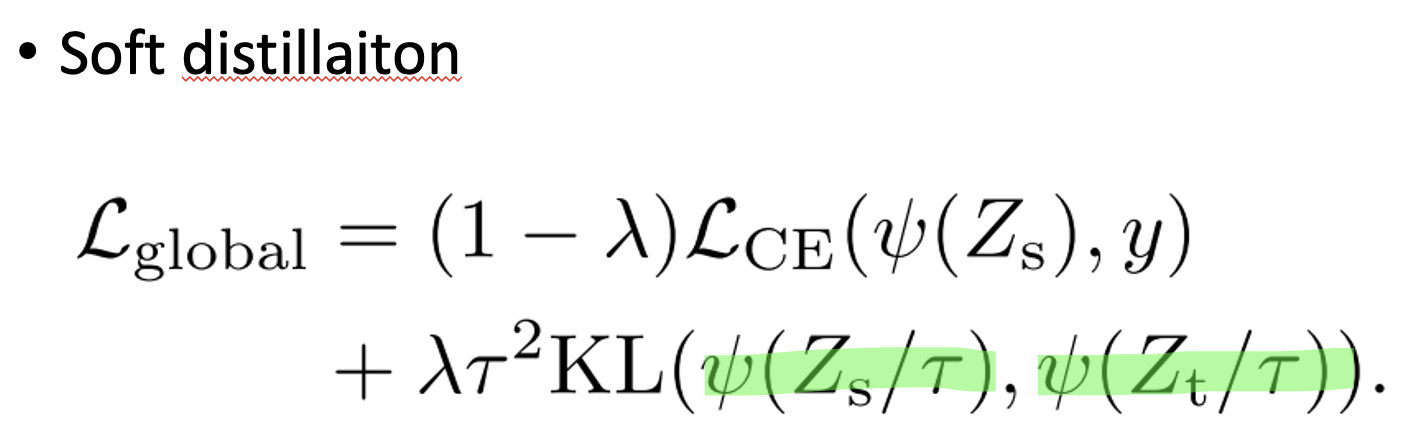
우선 soft distillation은 teacher 모델의 “softmax값”을 활용합니다. Teacher Model과 Student Model과의 Softmax 값의 KL Divergence Loss를 활용합니다.
parameter은 아래와 같습니다.


Hard distillation은 teacher 모델의 예측값을 직접적으로 활용합니다. 여기보이시는 yt가 teacher 모델의 예측값입니다.
Teacher Model에서 가장 큰 Softmax 값을 가진 Label을 True Label로 처리하여 Cross Entropy를 구하고, Ground Truth와의 Cross Entropy를 구해서 이 둘을 평균 내는 방식으로 Global Loss를 얻어내게 됩니다.
Soft distillation보다 직관적이고 실제 실험결과도 Soft distillation보다 좋은 성능을 얻어냈다고 합니다.
parameter은 아래와 같습니다.

Method: Distillation Token

다음으로는 본 논문에서 제안하는 방식인 distillation token 방식입니다.
기존의 ViT에서도 존재하는 class token과 이미지 패치에 distillation token을 추가한 방식입니다. 앞에서 더 좋은 성능을 보였다고 설명한 hard distillation 방식을 사용하여 output을 하나 더 도출했습니다.
이러한 방식으로 학습을 진행하였을 때, class token과 distillation token의 output의 cosine 유사도가 0.93까지 올라 distillation을 통해 teacher model의 정보가 전달되지만, 서로 다른 벡터임을 확인할 수 있었습니다.
이 distillation을 통해 최종적으로 Student는 Teacher와 비슷한 결과물을 내는 것이지 완전히 같은 결과물을 내는 것은 아니기 때문에 1보다 작은 0.93 정도의 Cosine 유사도를 가지는 것은 납득이 가능한 것 같습니다.
따라서, distillation token은 class token과는 다른 기능을 가지며, classification 성능 향상에 도움을 준다는 것을 확인했습니다.
반면에, 비교를 위해서 똑같은 target label을 가지는 class token을 단순히 하나 더 부착해 봤는데요.
처음에 분명히 초기값을 임의로 다르게 배정하였음에도 불구하고, 학습을 진행하면서 두개의 토큰은 거의 동일한 (cosine 유사도 0.999) 벡터로 Converge 되어 버리고, output 또한 사실상 같은 값이 나오게 되어 분류 성능에 전혀 영향을 미치지 않는 것을 알 수 있습니다.
'AI 논문 리뷰(AI Paper Review) > 컴퓨터비전(Computer Vision)' 카테고리의 다른 글
| [논문정리] DenseNet 개념 정리 (0) | 2023.09.01 |
|---|---|
| [논문정리] ResNet 개념 정리 (0) | 2023.09.01 |
| [논문 정리] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows (0) | 2023.09.01 |
| [논문 정리] AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE (0) | 2023.09.01 |
| [논문정리] Convolution Neural Network (CNN) 개념 정리 (0) | 2023.09.01 |



